Patent: Optimizing On-Device Transformer Inference for Source Code Checking
by David Spuler
ABSTRACT
A system and method for source code checking using a transformer neural network architecture allowing optimized on-device inference and reduced computational load for low-power platforms such as smartphones and PCs, by directly acting on the input programming language text without additional prompt instructions. Specifically, a method of edit decoding is defined for directly analyzing source code text using transformer-calculated probabilities to assess whether to accept a token or apply a correction. Another feature is an improved early exit algorithm that is faster and more accurate by using a reference token sequence in the exit decision logic, such as by analyzing input programming language text tokens in source code checking. In addition, the edit decoding method can be combined with the early exiting of transformer layers as a further optimization, whereby deep integration of the decoding algorithm with the input-based decision criteria for early exiting allows increased accuracy of source code checking while executing the optimized algorithm.
OPTIMIZING ON-DEVICE TRANSFORMER INFERENCE FOR SOURCE CODE CHECKING
TECHNICAL FIELD
The present invention relates generally to transformer neural network system architectures in artificial intelligence, and more particularly to optimizing the speed of transformer inference when performing source code checking of programming languages on low-resource computing devices such as smartphones, tablets and laptop computers.
BACKGROUND OF THE INVENTION
Artificial Intelligence (AI) is the field of designing software and hardware systems to make computer-based systems appear to act intelligently. Natural Language Processing (NLP) is the subset of AI involving understanding or creating natural language in text form.
The current state-of-the-art architectures for many NLP tasks use a transformer architecture as the computation engine and a model such as a Large Language Model (LLM) with billions of weights. A well-known example is the ChatGPT product using a Generative Pre-trained Transformer (GPT) architecture.
Transformer architectures are general-purpose neural network system architectures that can be used for a variety of NLP tasks. For example, a transformer architecture may receive input text representing a question and generate output text representing an answer. As another example, a transformer architecture may receive input text and generate output text representing an edited version of the input text. As yet another example, a transformer architecture may receive input text and output text representing a summary of the input text.
Transformer architectures may perform inference in different computer system architectures with one or more computer devices, and with or without a network. As one example of a computer system architecture with multiple computer devices and a network, the transformer architecture may execute inference in cloud backend system in an online system. In this case, users submit input queries remotely over the network to the transformer architecture that executes inference in one or more computer devices, which are called "servers" in the "data center". After computation by the transformer architecture, users then receive their output results back again via the network.
As another example of a computer system architecture with one computer device, the transformer architecture may execute inference on the same computer device that is used for user input, such as a user's smartphone, tablet, laptop computer, or desktop computer. The use of a transformer architecture in this way is called "on-device inference" because the transformer executes the inference computations directly on the user's device without needing network transmission. The transformer architecture's computations are returned to the user as output on the same device.
There is a long history of using computer methods to find errors in human-created text. Early spell checkers found errors in English language text, and more recently the research field of Grammatical Error Correction (GEC) or "editing" has emerged as a subset of NLP involving analyzing an input text to find and/or correct errors in spelling, punctuation, or other grammar issues, and furthermore for corrections to other higher-level problems such as omissions, inconsistencies, or factual inaccuracy. Many of these approaches are specific to syntactical issues in natural language text, such as English, but some of these approaches also have relevance to programming languages.
In the context of programming languages, examining program text to find error corrections to make is called "source code checking" or simply "checking," and the tool is called a "code checker" or simply "checker." Source code checking is the detection and correction of errors or deficiencies in source code text. Such corrections can be the detection of major defects causing the program to not perform in the manner expected, known as "bugs." This type of code checking is a subset of "debugging," which refers to the general discipline of finding and correcting program bugs, but there are other types of debugging techniques that don't use source code. Other types of source code checking include stylistic improvement matters or detecting issues related to security, portability, maintainability, or other aspects of the software.
Source code checking and grammatical error correction have some similarities, since both involve analyzing sequences of text for abnormalities, but there are various important differences. Programming languages have a much more rigidly defined syntactical and semantic structure, whereas natural language is more ambiguous and freeform. Hence, source code checking has some aspects that are "easier" than grammar checking of natural language.
Source code checking also has a long history, starting with early compilers that found errors in programming language source code, thereby acting unofficially as source code checkers. Whereas compilers emit warnings about corrections as a side-effect of compiling the program source code to machine code, there are also several approaches aimed specifically at identifying coding defects. There are several source code checking tools, both free and commercially available, sometimes known as "linters" (after an early "lint" tool on Unix) or more formally as "static analysis" tools.
Code checking can be used on a variety of computer programming languages, and the present disclosure may be used with any such programming languages, as embodiments. Different categories include procedural languages, which specify programmatic instructions, or declarative formats that include more static declarations of computer information. For example, procedural languages include many well-known high-level programming languages such as BASIC, Python, C++, and Java.
Whereas some prior art predates the transformer architecture, much of the latest research uses transformer architectures and LLMs for both grammatical error correction and source code checking. This use of transformer architectures for source code checking has been found to be advantageous in terms of accuracy and generality when compared to prior non-transformer methods. Non-transformer methods have more difficulty in "understanding" the full context and often do not generalize to complicated programming structures. Transformer-based algorithms are better at generalizing the rules of programming language syntax, handling issues across the full input text span, and making corrections based on semantics. Transformer architectures using LLMs have also been shown to be better at judging or verifying corrected programming source code.
The primary problem with transformer inference is the heavy computation costs for expensive computing power, such as with CPUs and/or GPUs, which is both costly and often results in slow response time latency and low throughput. Running transformer inference in a data center uses extensive GPU resources. These computation costs also make it difficult to efficiently run transformer-based inference on low-resource devices such as smartphones, tablets, and laptop computers, with adequate speed and response time. This efficiency problem is true of many transformer-based use cases in general, and also applies to the use of transformer architectures and LLMs for source code checking.
Beyond costly and slow computations, accuracy of output results is a concern. Transformer architectures have various accuracy limitations, such as hallucinations (false information), difficulty with mathematical reasoning, and the use of integrated add-on tools to correctly answer various types of queries. Not all of these accuracy issues are relevant to the source code checking use case, but source code has specific limitations that require a high level of accuracy from a source code checker.
One of the modules in a transformer architecture that can affect both efficiency and accuracy is the decoding algorithm. This is the tail-end optimization that chooses a token to output, after the predicted probabilities have been calculated. Making a correct choice in this decoding algorithm is useful for accuracy, and also for efficiency, because of the autoregressive algorithm used in transformer decoder stacks, whereby the decoder stack is executed sequentially in recurring iterations as controlled by the decoding algorithm at the end of each decoding cycle. Hence, the decoding algorithm has a disproportionate influence on the total speed of the transformer architecture.
Optimizing the decoding algorithm is one area in which to speed up transformer architectures. Many approaches to optimizing transformer architectures are described in the literature, such as quantization, pruning, and GPU vectorization, most of which are orthogonal to the use of faster decoding algorithms, meaning that the two optimization methods can be combined. Adaptive inference optimizations are a subset of transformer optimizations, whereby the computation pathway for inference is changed at runtime, depending on the input text.
Early exiting of layers is one such method of adaptive inference optimization, which is generally applicable to many transformer-based use cases, and can thus be used with source code checking and error correction. The idea is to exit computation of the decoder layer stack early, thereby avoiding many millions of computations from the skipped layers. Early exit optimizations are approximations that reduce the accuracy of results. Furthermore, the complexity within the exit decision logic can make them less than optimally efficient by not detecting all cases where they could exit and skip layers of computation.
SUMMARY OF THE INVENTION
The present disclosure examines methods to speed up transformer architectures in computing results of inference, particularly in performing source code checking tasks. Certain features of the disclosure also increase accuracy of results, by focusing the source code correction algorithms more fully on the input program text, thereby reducing excessive creativity and over-correction.
Although effective for transformer architectures running on any systems, this disclosure is particularly relevant to executing tasks on low-resource devices such as smartphones and personal computers, because it can speed up sequential on-device inference for CPU execution without a GPU, as well as improving efficiency of parallel execution in larger data center computers with powerful GPUs.
The present disclosure demonstrates these novel methods: (a) a specialized method for source code checking in transformer architectures called "edit decoding" that uses direct processing of the input text in the decoding algorithm to speed up inference, (b) the method of combining the novel edit decoding method with an early exiting method of layer optimizations, to further speed up transformer-based source code checking tasks, (c) a novel use of input text tokens, such as via their probabilities or ranking, in the decision criteria of an early exiting method, which makes an early exit optimization method faster and more accurate than prior art, with broad applicability to source code checking and other use cases, and (d) the further modified edit decoding method using a combination whereby this input-guided early exit decision logic is integrated with the edit decoding method.
The present disclosure of an edit decoding method aims to perform speed optimizations for source code checking using transformer inference in a way that is also more accurate than prior art. This is a checking-specific decoding algorithm that speeds up inference by utilizing the input text more directly in computing the output results, and also reduces inaccurate editing from over-correction by focusing the decoding algorithm directly on the input text.
According to Computer Science theory, a fully-capable programming language requires three main capabilities, allowing it to perform: (a) sequences of code instructions, (b) selection code instructions, such as if-then branches, and (c) iteration capabilities, which refers to looping constructs or, equivalently, to the ability to perform recursive function calls. In addition, programming languages may use many pragmatic capabilities, such as the ability to: (a) store data in memory, (b) receive inputs, and (c) display or print outputs. However, less powerful programming languages without all of these capabilities can also be useful, such as declarative languages. Declarative languages include configuration files, markup formats, and more generally any type of computer code that lacks the capacity in itself to perform or specify looping control flow structures (or their recursive function equivalent). Declarative languages may have the capability to perform sequence and selection control flow structures, although this is not always the case.
The present disclosure may apply to source code checking of programming languages with all of the three major capabilities (i.e., sequence, selection, and iteration), but may also apply to simpler computer code that lacks any of these capabilities. For example, a configuration file may simply allow setting simple values for configuration settings, thereby lacking all of the three capabilities. The use of such a simple configuration file will require such capabilities in a separate dynamic program that makes use of the data in the configuration file, but does not in itself specify such programmatic instructions.
Programming language files may be created or stored in different file formats, which are generally categorized as either: (a) source code, or (b) binary code. The source code format is a human-readable format, that is structured for computers to process, but is nevertheless amenable to human review, editing, and creation. Examples of source code include high-level programming languages, textual descriptions of if-then rule-sets, configuration files, and assembly language programs. The binary code format is intended for lower-level computer execution, and is not structured for human readability. Binary code formats include object code, machine code, and executable code formats. Code checking is aimed at error detection in source code formats, and the present disclosure of a novel "edit checking" method does not relate to error checking of binary code formats.
Edit decoding involves starting at the first token of the input text, without necessarily requiring an encoding or prefill phase. Subsequent tokens of the input text are compared against the computed probabilities by a transformer with an LLM. Where the input token is acceptable, it is output, indicating that no correction to the source code is detected. Where the probability of the input token is too low, or there is a different token with a much higher probability, then a different token to the input token is output (i.e. making a correction). In this case, the edit decoding algorithm then attempts to re-align the input with the output, so as to detect corrections that involve inserting new program tokens or deleting input tokens.
Edit decoding can be faster than prompt engineering methods of transformer-based source code checking on either sequential or parallel processing platforms because: (a) it does not use additional token processing for the extra prepended prompt instruction text, by directly processing the tokens of the input text, and (b) it allows for a reduced or avoided computation by the encoder or the prefill phase, rather than processing the entire input prompt.
Edit decoding can be executed on any computer system architecture, but is not necessarily faster in wall clock terms than parallel decoding algorithms, such as aggressive decoding or speculative decoding, on a multi-GPU parallel processing platform, such as in cloud data centers. However, edit decoding combined with early exiting is a viable speedup of on-device inference for source code checking on low-resource devices (e.g., smartphones), for either sequential or single-GPU parallel execution, whereas parallel decoding (including via speculative decoding or aggressive decoding) would actually increase computation loads on these devices.
Edit decoding is not a type of speculative decoding or aggressive decoding. These methods perform extra speculative computations on future lookahead candidate tokens, whereas edit decoding does processing of the current input token. Hence, edit decoding does not perform any extra "speculative" computations, which may be discarded and wasteful, and edit decoding is thus less compute-intensive than these methods. In addition, speculative decoding uses an extra "drafter model" whereas edit decoding may not have this extra overhead. Furthermore, by intricately linking the decision logic of the early exit algorithm to the source code input tokens, the accuracy can be significantly improved compared to other uses of early exit without this innovation.
The output of edit decoding might not be exactly what the un-modified transformer would have output, but is nevertheless correct and not an approximation. The output of edit decoding is one of the many possible valid outputs of that transformer, since the output tokens have a high-enough probability. The resulting output could have been chosen by the transformer if it were only using a standard decoding algorithm, such as randomized "top-k decoding" algorithm.
Edit decoding also has the advantage of reducing model creativity and over-correction, because the hard-coding of source code checking logic forces it to be focused on this task. Hence, the resulting output text is more likely to be closer to the original input program text, including its style and overall structure, thereby achieving a desirable avoidance of over-correction, such as excessive creativity or unnecessary changes, when doing source code checking with the standard decoding algorithms.
In order to further optimize the edit decoding algorithm, it can be further combined with early exit of layers in the transformer. This combination is faster than the edit decoding algorithm alone, because it is a dual speedup using two distinct techniques. Any of the variants of early exit, with their various types of decision logic, can be orthogonally used with edit decoding. For example, a simple criteria would be to exit whenever the model is predicting its next token with a probability over a threshold of 90% probability.
Early exit is an approximation, improving speed at a cost to output results. Hence, the use of early exit with edit decoding comes with some decline in terms of accuracy of the model output due to layers being skipped at runtime.
This accuracy problem can be reduced through a novel integration between the edit decoding algorithm and the decision logic for early exiting. The extra information available in a reference token sequence, such as the input text in the source code checking use case, allows the early exit decision algorithm to directly use the input text tokens and their probabilities in its logic. In this way, there is extra information available to optimize the early exit decision module and the early exit logic can be extended to become more accurate in terms of when to exit layers with output tokens. Hence, the transformer architecture can also exit earlier in its layers, with further efficiency gains when there is a direct match between the input tokens and the layer logits.
Certain features of the present disclosure can be combined and used together for further optimizations. Another aspect involves combining the new edit decoding algorithm for source code checking with the early exiting methods, and furthermore, with the specialized version of early exiting using input text as a reference token sequence.
BRIEF DESCRIPTION OF THE DRAWINGS
FIG. 1 is a high-level block diagram of a system environment for an online cloud system, in accordance with a number of embodiments of the present disclosure.
FIG. 2 is a high-level block diagram of a computer device, such as a computer server, smartphone or laptop computer, in accordance with a number of embodiments of the present disclosure.
FIG. 3 is a block diagram of a system for transformer inference, in accordance with a number of embodiments of the present disclosure.
FIG. 4 is a block diagram of an input module for a transformer, in accordance with a number of embodiments of the present disclosure.
FIG. 5 is a block diagram of an output module for a transformer, in accordance with a number of embodiments of the present disclosure.
FIG. 6 is a block diagram of an encoder-decoder transformer architecture, in accordance with a number of embodiments of the present disclosure.
FIG. 7 is a block diagram of a system for QKV attention in a transformer, in accordance with a number of embodiments of the present disclosure.
FIG. 8 is a block diagram of a Feed-Forward Network (FFN) module, also known as a Multi-Layer Perceptron (MLP), in accordance with a number of embodiments of the present disclosure.
FIG. 9 is a block diagram of a Multi-Head Attention (MHA) module, in accordance with a number of embodiments of the present disclosure.
FIG. 10 is a flow-chart of a method for autoregressive decoding in a transformer, in accordance with a number of embodiments of the present disclosure.
FIG. 11 is a flow-chart of a method for early exit optimization of a transformer, in accordance with a number of embodiments of the present disclosure.
FIG. 12 is a flow-chart of a method for edit decoding using a transformer for source code checking, in accordance with a number of embodiments of the present disclosure.
FIG. 13 is a flow-chart of an improved method for early exit, extended by current input token decision optimization, in accordance with a number of embodiments of the present disclosure.
FIG. 14 is a flow-chart of a method of evaluation and synchronization as part of edit decoding for using a transformer for source code checking, in accordance with a number of embodiments of the present disclosure.
FIG. 15 is a flow-chart of a method for integrating edit decoding and early exit in a transformer, in accordance with a number of embodiments of the present disclosure.
FIG. 16 is a flow-chart of a method for integrating edit decoding and early exit optimized with current input token decision logic, in accordance with a number of embodiments of the present disclosure.
The figures depict various embodiments of the present invention for purposes of illustration only. A person skilled in the relevant art will readily recognize from the following discussion that alternative embodiments of the structures and methods illustrated herein may be employed without departing from the principles of the invention described herein.
DETAILED DESCRIPTION OF EMBODIMENTS
The present disclosure relates generally to a transformer architecture, whereby many embodiments involve the use of a transformer engine method, consisting mainly of executable code instructions, and an associated LLM model, consisting mainly of data. Features of the disclosure herein may be applied to performing source code checking with such a transformer architecture, and some features may apply to other NLP tasks performed by an AI system.
Embodiments of the present disclosure may be implemented on a number of computer systems with different system environments or hardware architectures. In one embodiment that is used in commercial systems such as ChatGPT, the computer system involves a cloud-based architecture and a network, whereby the users communicate with a cloud-based AI system from their own user devices over the network. In another embodiment, the method may be performed on a computer system that is a single computer device, such as a personal computer, laptop, or smartphone. In yet another embodiment, the computer system may involve a hybrid architecture where some processing is performed on a user device and some processing is performed in a cloud-based system.
Transformer Architecture
Numerous different embodiments are possible using different transformer engines and different LLMs. Although some specific embodiments of transformer architectures are described in detail herein, there are many variants, extensions, and modifications that are used in the prior art, and continue to be created, and many of these embodiments are orthogonal to the features disclosed herein, allowing them to be used as embodiments of the invention. Similarly, there are many types of LLMs, both large and small, and having different structures, which can be used in embodiments of this invention.
The details of transformer architectures, including numerous variations, are well-known in the research literature, in commercial products such as OpenAI's ChatGPT and Google's Gemini, and also in fully-coded open-source transformer architectures and LLMs with billions of weights available for free on the internet. A brief discussion will be given here of transformer inference algorithms to motivate the improvements that the present disclosure describes, including improved efficiency by utilizing specialized features of the source code checking use case.
In many embodiments, the transformer engines are executable algorithms, and the models are files containing static data, including numeric weights that have been pre-calculated in a training phase using training data sets.
The methods for creating LLMs using training or fine-tuning have an extensive literature base. Many different training methods may be used to create an LLM to use with a transformer engine in an embodiment of the present invention.
Inference is the process whereby a transformer engine uses a model, which has already been trained, to answer an input query by creating an output response. The weights in the model are not usually changed during inference calculations.
The first major transformer in 2017 had two main components, an encoder and a decoder, and was called an encoder-decoder architecture. Subsequently, variants have been discovered including encoder-only architectures (without a decoder) and decoder-only architectures (without an encoder). Most state-of-the-art transformer architectures now use decoder-only architectures, such as GPT, although encoder-only and encoder-decoder architectures still have some relevant use cases.
Both the encoder and decoder major components consist of multiple layers, called the "encoder stack" and "decoder stack," respectively. An encoder-only architecture has no decoder stack, and a decoder-only architecture has no encoder stack. The number of layers in any stack may vary according to the model size and this is usually decided prior to training.
In many embodiments, each layer within each stack is identical in structure, with the same number of weights (but different values) and the same sub-components in each layer. However, other embodiments involve transformer variations where layers in the same stack can have different dimensions or structures.
Computation within each layer stack progresses one layer at a time. The output from one layer is used as the input to the next layer. After the final layer, the layer stacks are finished, and final output processing is performed.
Tensors are used for faster computations in transformer architectures, for both the attention and FFN computations. Tensors are multi-dimensional arrays of numeric data, where a vector is a one-dimensional tensor, and a matrix is a two-dimensional tensor.
Each layer in the decoder stack consists of sub-layer components with two main types: (a) attention heads and (b) Feed Forward Networks (FFNs), also sometimes called a Multi-Layer Perceptron (MLP). Other sub-layer components include normalization modules, addition modules, activation functions, and Softmax. The encoder-decoder architecture also has a cross attention module to coordinate between the encoder and decoder.
Each attention head in the transformer architecture consists of three major weight matrices, denoted as Q (query), K (key), and V (value). Attention heads may implement a self-attention algorithm or a masked attention algorithm, depending on in which stack they are located.
One well-known optimization to the QKV attention algorithm that is used in many embodiments of transformer architectures is called "KV caching." This involves a method of storing caches of the K and V tensors from one token cycle in the memory or secondary storage, and then subsequently to re-use this data in the next token decoding cycle by loading the data from memory or storage.
The FFN components also contain sub-components. In modern transformer architectures, FFN modules consist of two linear layers, each involving matrix multiplication using weights in a matrix, followed by an addition of a "bias" vector using different weights, with an intervening activation function module between the two linear layers. Many well-known activation functions may be used in a transformer architecture, such as RELU, GELU, ELU, Swish, tanh, and others in the prior art, of which RELU is more efficient to compute.
Before any of the layers are executed, there are initial input processing steps. The steps include tokenization of the input text into a sequence of tokens (integral numbers) based on pre-defined token strings called the "vocabulary" of the model (e.g., 50,000 different strings).
Compilers have been tokenization programming language text for many decades, so it is a well-known task. Tokenization of source code has some differences compared to tokenizing natural language. For example, programming languages have keywords with special meanings (e.g. "if"), and also certain multi-character punctuation sequences that have a special meaning (e.g. "++" means increment in C++), and these would usually be tokenized as one token.
The next step after tokenization is converting each of these single-number tokens into a vector representation called "embeddings" (usually via multiplication by an embedding matrix, learned during training), thereby creating a vector of vectors, which is a matrix. One dimension is the embedding vector size and the other is the token sequence length, or length of the maximum context window if this is less than the sequence length. This embedding representation is then merged with positional embeddings (based on cosines or other variations), and then this matrix is passed into the first transformer layer.
Transformer inference runs in two major phases. In encoder-decoder architectures, the first phase is the encoder, and the second phase is the decoder. In decoder-only architectures, the first phase uses the decoder stack to perform an encoder-like function and this is called the "prefill" phase. Both of these phases are computation-heavy as they process the entire input token sequence, and one cause of inefficiency and slow response times is the encoding or prefill phases of inference. This first major phase of encoding or prefill is usually preparatory, such as to create the internal representations and KV caches for the input text, and does not output a token for an encoder, or may output the first token for the decoder-only prefill phase.
The second major phase in both encoder-decoder and decoder-only architectures is called the "decoding phase", and in its best-known embodiment involves selecting an output token one at a time, which is called an "autoregressive decoding algorithm." For encoder-only architectures, the second major phase is not similar to the autoregressive decoding algorithm, and there are various other well-known post-encoding computations possible.
After the layers have been computed, there is a final output processing stage that emits a single token. The calculated results from the layers are still in embeddings format, requiring an "unembedding" step that converts the embeddings back to token probabilities via a linear layer (i.e. matrix multiplication and optional bias).
This vector of values from the unembedding computation is then processed by Softmax normalization to create a valid probability distribution of the predicted token probabilities (called "logits"). The output of Softmax is a vector of probabilities, with one value for each token in the vocabulary, where each probability is in the range [0,1] and the token probabilities sum to one.
A decoding algorithm is then used to analyze the probability distribution of the tokens, and to choose one of these tokens to emit. The present disclosure includes demonstration of some enhancements to decoding algorithms and they are examined in further detail below.
Source Code Checking
Source code checking suffers from efficiency problems when using a transformer architecture based on an LLM. To perform source code checking or other tasks on a device uses inference, and it is desirable to run the transformer directly on the computing device. Otherwise, there is the additional cost and time delay of transmitting network messages between the device and cloud servers. However, it is difficult to efficiently run transformer architectures on low-resource devices such as smartphones, tablets, and laptop computers, because they use so many billions of computations. Embodiments of the present disclosure relate generally to improving the speed of inference for a transformer, such as when performing source code checking. Certain disclosed methods may be advantageous for on-device inference, where they can speed up sequential execution on a CPU-based device without a GPU.
The input and output texts for transformer architectures vary significantly across use cases. Creating a draft outline may emit a long output text from a short input prompt. Summarizing a long text down to a few sentences converts a long input to a short output. The source code checking use case is different in that the input and output are of similar length, and contain relatively few changes, because the goal is to make minor edits to the input. This property of input-output similarity allows specialized algorithms to be used to speed up source code checking inference in certain features of the present disclosure.
The state-of-the-art in source code checking research is the use of transformer architectures and LLMs for code checking tasks. Several major methods of using transformer architectures for source code checking have been considered in the prior art, including: (a) specially trained or fine-tuned LLMs, (b) prompt engineering optimizations, and (c) checker-specific decoding algorithms.
Several checker-specific LLM models have been created by researchers based on training data sets that are specific to source code checking, with some success in accurately correcting input text. This includes both smaller LLMs trained with specialized source code checking data sets or large general-purpose LLMs fine-tuned with such data.
There are two main categories of checker-specific models: (a) sequence-to-sequence models, or (b) sequence-to-edit models. Sequence-to-sequence models emit the corrected final text as output text. Sequence-to-edit models emit a type of marked-up text, using markup tokens to indicate editing changes, such as to insert, delete or modify a token.
Another transformer-based approach that can be used for source code checking, either with these specialized LLMs or with general-purpose LLMs, is "prompt engineering" whereby the model is given prompt instructions that tell it to perform source code checking tasks. These additional prompt instructions in natural language are prepended or appended to the input text, so that the full LLM prompt text contains both the requested actions and the input context.
Both methods of transformer-based source code checking with specialized LLMs or prompt engineering with prompt instruction injection suffer the primary problem of inefficiency from too many computations for a full model inference, necessitating the use of many advanced GPU chips for inference, which is expensive. These computation loads also make executing transformer inference for source code checking problematic in terms of response time (latency) and throughput on low-resource devices such as smartphones, tablets, laptop computers, and low-end PCs, which may have no GPU, or may have a single low-capability GPU. Prompt engineering techniques that add extra prompt instructions exacerbate this inefficiency by adding extra prompt tokens to be processed in the input.
Transformer architectures used for error correction with prompt engineering on general-purpose LLMs also have a tendency to over-correct with more elaborate code structures, which is useful in some contexts where advanced coding is desirable, but can be undesirable and excessive in use cases such as teaching students how to program better.
Furthermore, transformer architectures have a tendency to insert creativity into any text, rather than making focused corrective or other minor changes. This again can be useful in some contexts like creating new programs, but undesirable in others, such as revising old code to reduce technical debt.
These problems with over-correction and creativity can be reduced by using more detailed prepended prompt instructions to the LLM, such as to ask it to make minimal changes or to omit non-corrective changes. Although this may improve results, this adds further additional cost for processing of extra prompt instruction tokens by the transformer.
Decoding Algorithms
The present disclosure of an "edit decoding" method relates to improvements to decoding algorithms that replaces the prior art decoding algorithms when performing source code checking. The fact that input and output text are closely related in editing allows a special-purpose decoding algorithm for source code checking to be more efficient than general-purpose decoding algorithms.
The decoding algorithm is the last step in a transformer before outputting a token. Decoding algorithms in transformer architectures work as follows. One full cycle of transformer inference is a full decoding cycle, as described above, outputs a vector of probabilities that indicate which token should be output with what predicted probability. A full decoding cycle may execute all layers of a model, or some may be skipped, such as by early exiting of layers. The decoding algorithm is the method at the end of the full decoding cycle, after of one or more layers, whereby the transformer chooses a token to output from the list of token probabilities.
The present disclosure of a novel decoding algorithm called "edit decoding" relates to optimizing the decoding algorithms of transformer inference for source code checking tasks. checker-specific decoding algorithms are one attempt in the prior art to try to speed up inference when performing source code checking. In this way, prepended prompt instructions to the model are not used, because its performance of source code checking tasks is hard-coded into the decoding algorithm. Computation is faster by not needing to perform the model computations for these extra prepended prompt instruction tokens.
There are several types of decoding algorithms known in the prior art, most of which are not specific to source code checking. The greedy decoding algorithm simply chooses the token with the maximum probability. The top-k decoding algorithm chooses randomly between the k tokens having the highest probabilities, which is more flexible and creative than greedy decoding. The top-p decoding algorithm modifies top-k decoding to avoid choosing any tokens with probabilities below a threshold, which may involve choosing from less than k tokens. These decoding algorithms usually consider the probabilities of one token position without any "lookahead" to future tokens.
Beam search decoding is another well-known decoding method that is more advanced as it uses "lookahead" to defer the decision on which tokens to output until it has seen more than one token ahead, which can be more accurate in outputing multi-token sequences of multiple tokens.
The main problem with these decoding algorithms is that they are inefficient because they are "autoregressive" algorithms, whereby any token that is output, is then reprocessed as input by the entire transformer in the next decoding cycle. For example, when the transformer has already processed N tokens, the autoregressive algorithm performs the steps: (a) generate the N+1th token from intermediate output tokens 1..N, with a full cycle of the transformer stacks, involving billions of computations; (b) for the next token, the N+2th token, the N+1th token is added to the intermediate output, and the tokens 1..N+1 are used in a full transformer cycle to produce the N+2th output token.
Only one token at a time is produced, sequentially, by this autoregressive decoding method. The topmost progression of this algorithm cannot be sped up by parallel computation because each decoding cycle is waiting on the output token from the prior decoding cycle. GPU chips can parallelize many lower-level computation steps within each transformer cycle, but this major high-level bottleneck in the decoding algorithm is hard to overcome.
There are various methods in the prior art that create "non-autoregressive" or "parallel decoding" algorithms, such as aggressive decoding, lookahead decoding, lookup decoding, or speculative decoding. Aggressive decoding is specific to grammatical error correction or source code checking, whereas the others relate to general transformer use cases.
Aggressive decoding refers to using the input context as a reference token sequence, which is then validated by a larger model using parallel computation. Speculative decoding involves creating a reference token sequence using a smaller model, an optimization of the larger model, or another approximation or compression method applied to a large model. A subtype of speculative decoding called "generalized speculative decoding" refers to creating a reference token sequence through non-model based approaches, such as language-based heuristics. Lookup decoding involves searching for a reference token sequence in a set of documents or a datastore by searching for a subsequence. A subtype of lookup decoding is "prompt lookup decoding," which involves finding a reference token sequence in the context of the prompt input, by searching for a subsequence. Lookahead decoding refers to generating multiple predicted future tokens as a reference token sequence.
One problem with these prior art decoding algorithms is that several of these parallel decoding algorithms use an additional second transformer model, called a "draft model," which is usually smaller and faster than the main transformer, but executing the draft model is nevertheless extra processing overhead.
These parallel decoding methods perform extra processing in parallel across multiple GPUs, aiming to speed up the latency (response time) for the user. Although this is faster in wall clock terms, it actually increases the overall GPU processing load (in parallel), making it more costly to run.
Furthermore, these prior art parallel decoding algorithms are not effective in low-resource on-device inference, such as smartphones, where there are not multiple GPUs to perform parallel processing. Even to the extent that a device has some parallel execution capability, such as in the CPU's SIMD code instructions or a Neural Processing Unit (NPU), it is unlikely to have enough capacity. Even if it does, then the overall increase in load from parallel processing will overload the device, causing problems such as a "frozen phone," overheating, or battery depletion.
The novel edit decoding algorithm improves on prior art decoding algorithms by: (a) executing faster in terms of total execution time; (b) starting to emit output tokens sooner by reducing or avoiding prefill time; (c) processing fewer tokens overall than parallel methods, thereby reducing overall compute cost; and (d) improving accuracy of correction markup results by reducing the level of excessive creativity and over-correction.
The present disclosure of an edit decoding algorithms has certain limitations: (a) the autoregressive decoding bottleneck is not fully alleviated, which limits the extent of parallel processing; (b) the method does not use lookahead to multiple future tokens, which limits its accuracy in terms of multi-token source code corrections; (c) it does not always make the correct suggestions; (d) may be inaccurate at the first token, or the initial statement; (e) loses some ability to make higher-level semantic corrections; and (f) although it can often improve accuracy, the method can nevertheless still sometimes emit inaccurate or unnecessary corrections.
The present disclosure of an edit decoding method relates to improving the decoding algorithm. In most embodiments, the decoding algorithm is the last phase of inference, and is orthogonal to the rest of the transformer software architecture. Decoding algorithms including the present disclosure may be used for encoder-decoder, encoder-only, and decoder-only transformer architectures. Furthermore, decoding algorithms may be used on any past or future transformer variants or non-transformer software architecture, whether neural network or otherwise, provided that it computes probability predictions about the next token to emit.
Early Exit
Early exiting of layers involves exiting processing in a layer stack before the remaining layers have been computed, so as to speed up transformer execution. Research has found that the initial layers tend to make the big decisions about tokens, whereas the final layers are usually finessing between a few acceptable tokens. This motivates the idea to stop computing layers as soon as a layer has computed a viable output token. This is a dynamic adaptive inference optimization, with the decision to exit made at runtime, rather than statically by permanently removing some layers from the model file.
Adding early exit of layers to a transformer architecture is relatively easy. It is convenient because each layer of a model has the same size input and output, so any layer's output can be sent to the unembedding module and, if exiting, then to the final output processing steps. However, one of the downsides is the additional computation for "unembedding" and exit decision logic at potential layer exit points, but this is usually less than the gain from skipping layers.
In a transformer without early exit, the unembedding logic takes place after the layers have been computed. Unembedding involves a linear transformation using an "unembedding matrix" and a Softmax normalization to convert the embedding vectors into numeric token probabilities for each token, which are called "logits" and are output as a vector of probabilities for each token in the vocabulary. The unembedding matrix can be the matrix inverse or matrix transpose of the embedding matrix.
Softmax normalization is a well-known method that normalizes the unembedding values into a valid probability distribution, where each value is in the range [0,1] inclusive, and the probabilities sum to one. The Softmax method involves (a) exponentiating each vector element, (b) computing the sum of these exponentiated values, and (c) scaling each element of the new vector by this sum.
In an early exit transformer, the unembedding logic may be added to any layer where the model may decide to exit early, along with an "early exit decision" logic module that decides whether to exit at that layer. For early exiting after a fixed number of layers, the decision logic is simply a comparison of the layer count against a fixed number, without using the token probabilities, and therefore does not use an extra unembedding calculation. However, early exit decision modules that are based on token probabilities use the probabilities calculated as "logits" by an unembedding module and Softmax module at that layer.
Another implementation detail is that early exiting causes problems with the KV cache optimization. Any layers that are skipped by exiting early do not get their KV cache computed in that decoding cycle, and will be out-of-date in the next token's decoding cycle. Whenever an early exit is taken, any layers that are skipped have the cache marked as out-of-date.
Several methods to do early exiting without disrupting the KV cache are reported in the literature including: (a) recomputation, (b) propagation, or (c) prevention. One method is simply recomputing out-of-date KV caches when detected, although this is inefficient from the recomputations and tracking out-of-date KV cache values.
More efficient than recomputation is propagating the current layer's KV cache data to the skipped layers when early exiting, which ensures there is a KV cache, but the cached values from a different layer are an approximation of the cache that would have occurred if the remaining layers were fully executed. This propagation method is efficient by avoiding recomputation, and the byte copying for propagation can optionally be further optimized by using a pointer or offset method of indirection to track which layers of the KV cache should get which data blocks from the KV cache.
Even more efficient than correcting the KV cache after early exit is modifying the early exit algorithm to completely prevent out-of-date KV caches from occurring. For example, this is possible by: (a) using early exit after a fixed number of layers or (b) exiting after a monotonically decreasing layer count as the token sequence progresses. Another possibility on systems where the KV cache memory is excessive is simply to avoid using a KV cache at all.
Early exiting aims to be faster because it simply does not compute some of the layers, which may involve many millions of weight computations. However, it damages the accuracy of the results of the transformer, meaning that the output text is not as good as the full non-exited layer stack. Hence, various decision methods have been developed to decide whether or not the currently predicted tokens are accurate enough to allow an early exit.
Various methods of implementing early exit have been reported in the research literature, with the decision to exit a layer based on logic such as: (a) exiting after a fixed number of layers, (b) exiting when there is a token with a high-enough predicted probability, (c) exiting when the predicted probabilities of the tokens are stable between layers, (d) exiting when the difference between the highest and second-highest predicted probability is above a threshold, and (e) numerous other minor variations on these methods.
Token-Specific Early Exit
The present disclosure demonstrates an advanced version of early exit whereby the decision logic incorporates the probabilities or rankings of tokens in a reference token sequence, such as the current input tokens when performing source code checking. The current input token is the current reference token, referring to the first token in the reference sequence that is based on the current input sequence.
This novel approach of focusing early exiting decisions on reference tokens from the input text improves overall efficiency by often allowing earlier exiting than with prior art early exit decision algorithms. The percentage of early exit modules that decide to exit early is increased, which increases the number of skipped layers, thereby improving the overall efficiency of the transformer architecture. This method is not necessarily specific to source code checking, but can be applied to this use case by using the input text as the reference token sequence.
The predicted probability of the input token is available for early exit modules. The logits for tokens are known after any layer, whereby the "unembedding" and Softmax calculations are performed after the layer is calculated. Hence, the probability for the current input token within the edit decoding algorithm is immediately available in the logits. The decision logic can use a test based on a probability threshold or a top-N ranking for the current input token. The threshold value should usually be low (e.g., 5%) or the N value for the top-N ranking be high (e.g., top-20), because there are often many valid tokens at a given point in a text.
A full unembedding computation via an unembedding matrix is used to compute the logits, even though this early exit criteria can use the probability of a single token, the current input text token. It is possible to get a single numeric value by a vector dot product of the current embedding vector multiplied by the unembedding matrix row specific to the token number of the current input token. However, this value is not a probability, but is a log-scale number of unclear significance because its relative magnitude to other results is unknown. This value is exponentiated and then scaled using the sum of the exponentiated values in the Softmax module. Unfortunately, the full unembedding matrix computation is used as input to Softmax normalization, so as to compute the predicted probability of the single input token. Hence, the method of using a single input token's probability does not make the unembedding calculation for early exit any faster, but can nevertheless improve decision accuracy, which allows exiting at an earlier layer, thereby improving overall model efficiency.
The use of input tokens in early exit decision logic is specific to use cases where there is a reference token sequence, such as the input text in source code checking use cases. General early exit methods in other use cases without a reference token sequence have no tokens to compare against when examining the logit probabilities. Hence, source code checking and other use cases with a reference token sequence can use token-based early exit and add more specific logic to the early exit criteria such as: (a) whether the input token has a predicted probability higher than a threshold, and/or (b) whether the input token is amongst the top-N predicted logits.
As an example, a generic early exit criteria might be to exit when the predicted token is 80% probability, but the source code checking task could set a lower threshold to allow the input text token has a 20% probability. This will allow the early exit decision to occur at earlier layers in cases where the model is predicting the input token is correct, and won't be edited, thereby allowing faster inference by exiting layers sooner on well-written input text.
The goal in this input-based early exit decision in the checking use case is not to necessarily find the best token to output, but to validate whether the current input token in the input text is "good enough" to be a valid token in the current program statement. Rather than change the token to an optimal one according to the model, this method can detect cases where the current input token is adequate and stop quickly and efficiently. Note that in some cases, the token considered optimal by the transformer architecture may actually be non-optimal in terms of over-correction or excessive creativity.
This novel early exit criteria will be efficient when the input token is correct. In such cases, the model's predicted token and the input token will match, and the model can exit very early. For example, if the model's predicted token is above 20% probability and it matches the input token's value, then the model can exit earlier than normal, even though it is not 90% certain. Overall, any text with few corrections will have a high rate of early exiting. Hence, the method will be very fast on correct or near-correct input text.
In cases where the current input token is wrong, representing a source code error, then the decision logic will report a low probability and too-high top-N value for that token, and the model layers will be executed to find the best correction. The input token and predicted output token will not match at any layer, and the model may finish processing the remaining layers, which is inefficient. However, since erroneous token corrections are assumed to be relatively infrequent compared to correct tokens, early exits of layers should be common, and the algorithm much more efficient on average with many layer computations skipped.
Furthermore, in such cases of a source code correction, the general early exit criteria can still trigger, such as when the model has a high-enough confidence that its predicted correction is accurate. A variation of early exit to address this inefficiency is to combine the basic early exit decision logic with this input-specific early exit decision logic. For example, where the model is reporting consistently that the current input token is not "good enough" to allow early exit, with another token being recommended as the highest probability, the method could still exit the layers with a correction to the better predicted token, without calculating all layers of the model. For example, if the model's predicted token doesn't match the input, but the predicted probability of an alternative token is above a 90% threshold, then the model can exit early and emit the corrective token. Similarly, if the probability or top-N ranking of the input text token is too low after a reasonable number of layers, the method could make the decision that it is likely incorrect, and then choose one of the better tokens as recommended by the model in the logits.
Note that the novel early exit decision method applies not only to sequence-to-sequence transformer models, such as the normal use of transformer architectures that output corrected text, and also to sequence-to-edit methods that output marked-up text. As with sequence-to-sequence models, the early exit method herein will be efficient for sequence-to-edit models when the input text is nearly correct. Sequence-to-edit methods contain markup tokens in the output. Hence, if the model is predicting no edits in a sequence-to-edit model, the output will be a normal non-edit token, and should match the input token, allowing early exit according to the novel method herein.
As with sequence-to-sequence corrections, input tokens requiring corrections will be slower in sequence-to-edit methods. If the model is predicting a corrective token, whether insertion, deletion or modification, then the early exit criteria based on the input tokens do not match. Hence, for corrections, it may be helpful to process the remaining layers of the model, or at least until the more general criteria for early exit are met.
Overview
The novel methods presented herein include: (a) edit decoding, (b) adding early exiting to edit decoding, (c) early-exit decision logic based on input tokens in edit decoding, or otherwise in various use cases, and (d) combined edit decoding with input-token based early exit decision logic, all have hyper-parameters such as thresholds or top-N ranking values. For example, the threshold for a token could be 0.5% probability or higher than top-200 ranking. Although these methods can be performed with many reasonable settings, the optimal value of these hyper-parameters may vary according to the precise use cases, the chosen transformer architecture and LLM, and the source code types to be processed in source code checking tasks, or input prompt characteristics in other tasks.
Furthermore, there are multiple criteria to be assessed in determining what is optimal, such as there is a trade-off between processing speed and output accuracy. The characteristics of the algorithm in terms of speed versus accuracy may vary with different projects. Testing with well-known benchmarking data sets, either commercial or open-source data sets, may be useful to evaluate the speed and accuracy of a transformer architecture using these new algorithms, testing different values of these hyper-parameters, so as to choose the hyper-parameter values for the project's characteristics.
All of these exit decision methods have varying speed improvements versus accuracy loss trade-offs. The presently disclosed methods speed up inference in the source code checking use case via both edit decoding and early exit methods, and also both improves output accuracy and reduces over-correction by focusing the early exit decision logic in error correction tasks on the input text tokens.
Detailed Description of the Drawings
The diagrams in FIG. 1 through FIG. 16 demonstrate embodiments of the present disclosure. These are now described in detail.
FIG. 1 is a high-level block diagram of a system environment for an online cloud system, in accordance with a number of embodiments of the present disclosure. Users interact with the user devices 120A and 120B, which will include methods of input and output available to users of the cloud-based AI system. Users submit inputs such as text to the input devices on user devices 120A/120B, and it is transmitted over the network 100 to the backend cloud system 110. After processing the query, either partially or fully, the backend system sends the results back to the user over the network 100 and the user receives the results of their AI requests on output displays on their user device 120A/120B.
The cloud system 110 performs the "backend" processing of the algorithm, such as by executing a transformer engine with an LLM. This cloud system comprises one or more computer servers, whether physical or virtual, each of which may contain a number of CPU components, GPU components, memory components, storage components, and other standard computer components. Cloud system servers may not have a user interface for input or output, other than via the network, although they may also have local interfaces for administrative use.
FIG. 2. Computer Device
FIG. 2 is a high-level block diagram of a computer device, such as a computer server, smartphone or laptop computer, in accordance with a number of embodiments of the present disclosure. The computer device 200 comprises may be physical or virtual, and may contain a number of CPU components 230, memory components 240 (e.g., RAM memory), storage components 250 (e.g., disk drives or solid state drives), and other standard or optional computer components, such as GPU components. When used in an AI system, the transformer engine is executed, using its LLM, on the same device as one or more user input devices 210 (e.g., mouse, keyboard) and one or more output devices 220 (e.g., monitor), without sending user queries over an external network.
FIG. 3. Transformer Inference
FIG. 3 is a block diagram of a system for transformer inference, in accordance with a number of embodiments of the present disclosure. Input requests from a user, such as text, are sent via the input module 310 to the transformer system 300 for processing, and the results are returned to the user via the output module 330. Inputs and outputs may be in the form of text, images, video, other data formats, or any combination thereof. At a high level, the transformer system 300 comprises one or more transformer engines 320 and LLM models 340. There are numerous variants and embodiments of a transformer engine 320, and various non-transformer AI engine architectures may also be used. Similarly, many LLMs may be used as embodiments, and smaller models and other non-LLM models may also be used in place of an LLM model 340 in this embodiment.
FIG. 4. Input Module
FIG. 4 is a block diagram of an input module for a transformer, in accordance with a number of embodiments of the present disclosure. Input text 400 is submitted to the tokenizer module 410, which uses the vocabulary data 417, consisting of a mapping of text strings to numeric token values, which is stored in the LLM 415. This tokenization method converts the input text into a sequence of numeric tokens, called a "token stream". There are many possible methods of implementing a tokenizer well-known in the prior art for both programming language tokenization and AI model tokenization.
This input token stream is converted to vector embeddings, where each token is represented by an embeddings vector, consisting of multiple numeric values stored in an array or vector. This is achieved by using the embedding matrix 416, stored in the LLM 415, by first converting each token into a "one-hot vector", which is a vector consisting of zero values except a one value in the index location equal to the token value. These one-hot vectors are combined to create a matrix, with one matrix row per input token value. This matrix of one-hot vectors is multiplied with the embeddings matrix via matrix multiplication in the MatMul module 420.
An efficiency improvement to this one-hot vector MatMul 420 is to note that it is equivalent to directly extracting the row or column corresponding to the token value from the embeddings matrix (depending on whether the matrix is stored in row-major or column-major order), thereby using one row or column per token. Hence, this row or column data can be directly extracted as the embeddings vector for a token, thereby avoiding a costly matrix multiplication computation.
The embeddings created by the MatMul module 420, or the optimized row/column extraction method, and may be optionally added to additional positional encodings 440. The positional encoding adds location-specific numeric values, according to the index position of a token in the sequence. There are several positional encoding methods well-known in the prior art, including the use of recurring sine and cosine functions. The positional embeddings data created by the positional encoding module 440 are added together in the matrix addition module 430 to create the final embeddings data 450.
FIG. 5. Output Module
FIG. 5 is a block diagram of an output module for a transformer, in accordance with a number of embodiments of the present disclosure. The output module works conceptually in reverse to the input module, by converting from embeddings 500 back to tokens, and then finally back to output text 550 for display. The embeddings 500 are the calculated internal output results of the transformer, or from an earlier non-final layer of a transformer if early exiting occurs.
Each embeddings vector is converted to numeric values in the unembedding MatMul module 510 using a matrix multiplication using the unembedding matrix 517 in the LLM 515. The unembedding matrix 517 can be the inverse matrix or transposed matrix of the embedding matrix 416 in FIG. 4. The output result of the unembedding MatMul module 510 is a proportional representation of the predicted tokens, but the values are not proper probabilities. These numbers are then normalized into a vector of "logits" representing the predicted probability of each token, using the Softmax module 520. The Softmax algorithm is well-known in the prior art, involving exponentiating each element of the vector, and then scaling each element using division by the sum of these exponentiated values.
The output of Softmax 520 is input to the decoding algorithm 525. Note that the "decoding algorithm" 520 is a sub-component of a "decoder" in a transformer, despite the similarity in terminology. The decoding algorithm takes as input the vector of probabilities for each of the tokens in the vocabulary, and outputs a single chosen token. Several decoding algorithms are available in the prior art, and a novel decoding algorithm method is disclosed herein. The simplest decoding algorithm is "greedy decoding" where the token with the highest probability is output, and the corresponding text string can be output immediately. A more complex decoding method is "beam search decoding" whereby the token is not output immediately, but is deferred until the beam search method has considered the probabilities of multiple possible multi-token output sequences, which is expensive to execute but can be more accurate in some cases.
The output token value that is chosen by the decoding algorithm, once it is finally approved for output, can be converted to text using the vocabulary data 516 of the LLM 515 in the untokenizer module 530. Untokenization can be efficiently implemented for a token value by using an array of text strings based on the tokens in the vocabulary data, and using the token value as an index to access into this array. The resulting text string is added to the output text 550.
FIG. 6. Encoder-Decoder Transformer
FIG. 6 is a block diagram of an encoder-decoder transformer, in accordance with a number of embodiments of the present disclosure. This shows the two major components, an encoder stack 670/665 and a decoder stack 610/615, in addition to the input module 601 and output module 660.
The encoder stack consists of N "layers", the first encoder layer 670 and a number of additional layers 665. In many embodiments, each encoder layer is identical, but in some embodiments the layers may have different structure.
Encoder output 675 is the intermediate results computed by the encoder layers, as tensors or matrices in the internal embeddings format, representing the K keys data and V values data. This output of K and V data is passed from the encoder layers to the decoder layers, for use in the cross attention module 630. In many embodiments, the K and V data from the encoder may be cached using the well-known "KV cache" optimization to avoid recomputation where the data is already available.
The decoder stack also consists of N layers, the first decoder layer 610 and a number of additional decoder layers 615. The decoder layers have a different structure to the encoder layers, such as having a cross attention block 630 that receives the output from the encoder into the decoder layer. In a different embodiment using a decoder-only architecture, there is no encoder stack, and the cross attention module 630 may be removed from decoder layers.
The decoder stack may have the same number of layers as the encoder stack, or it may have a different layer depth, such as the "deep encoder, shallow decoder" architecture where the encoder stack has more layers than the decoder stack. In many embodiments, each decoder layer is identical, but in some embodiments the layers may have different structure.
There are several "add & norm" blocks in the encoder layer (603, 605) and the decoder layer (625, 635, 645). These perform two actions: (a) addition of the input and output of the block via a residual connection, and (b) normalization of the data.
The addition computation is an element-wise matrix or tensor addition of the input and output of the block. The input data is available via a Residual Connection (RC) pathway prior to the computation block.
A pathway of a Residual Connections is used at several places in the architecture, around various computation blocks in the encoder stack (681, 682) and in the decoder stack (684, 686, 687). A residual connection takes a copy of the input data prior to a computation block, and then adds it to the output of the block after the computation. This addition of the input and output via a residual connection is helpful in optimizing training by reducing or avoiding the "vanishing gradient" problem, but some embodiments dispense with residual connections. If residual connections are used in training, they are retained in the architecture for inference.
Normalization of the data may use several well-known methods from the prior art as embodiments, such as the batch normalization method ("BatchNorm") or layer normalization method ("LayerNorm"). In different embodiments of the architecture known as a "pre-norm" architecture, the normalization computation may occur prior to computation blocks on their inputs, rather than afterwards on their outputs.
The Feed-Forward Network (FFN) is a sublayer component in many transformer architectures. An encoder-decoder transformer may include the encoder FFN 604 in the encoder layers 670/665, and the decoder FFN 640 in decoder layers 610/615. The details of the FFN architecture are shown in FIG. 8 and its description. The encoder FFN 604 and the decoder FFN 640 use the same method, but with different weights.
Each encoder layer has a self attention block 602, and decoder layers also have a self attention block 620. This cross attention module is used to pay attention to token computations using data from prior layers, also using data from the KV cache, if available.
Decoder layers in the encoder-decoder architecture in FIG. 6 also have a cross attention block 630. The cross attention block in decoder layers takes inputs that are the outputs from encoder layers. Since the encoder layer attention computations are not masked, whereas the self attention modules in decoder layers are masked, this cross attention method allows the decoder to indirectly pay attention to lookahead tokens. A decoder-only transformer architecture embodiment would remove the cross attention block 630, along with the encoder layers 670/665, but would then allow lookahead attention in the prefill phase.
The details of the QKV computation for attention modules, both self attention and cross attention, is shown in FIG. 7 and its description, and the Multi-Head Attention (MHA) optimization is shown in FIG. 9 and its description. The details of the KV cache optimization for self attention and cross attention modules are also discussed in those sections.
The first steps of this method shown in FIG. 6 occur in the input module 601, which converts input text formats into numeric tokens and then into an embedding vector internal format, which is used for computations in encoder layers and decoder layers. The input module 601 is as shown in detail in FIG. 4 and the corresponding description.
The final results of the decoder layer stack at the end of a full decoder cycle are sent to the output module 660 for processing. The embeddings internal data format is converted to token formats via an "unembedding" method shown in FIG. 5 and its discussion. When executing in autoregressive decoding phase, the output token may be: (a) emitted to output text 640 by untokenization from tokens to text strings, and (b) sent along the autoregressive token pathway 650, where the new output token is added to the intermediate output 600 for use in the next full decoding cycle. The output module 660 is as shown in detail in FIG. 5 and the related description.
Another embodiment of a transformer similar to FIG. 6 is a decoder-only transformer architecture. A decoder-only transformer does not have any encoder layers 670/665, and also does not use cross attention modules 630, which are based on encoder output 675, nor does it have corresponding add/norm module 635 or residual connection 686.
FIG. 7. QKV Attention
FIG. 7 is a block diagram of a system for QKV attention in a transformer, in accordance with a number of embodiments of the present disclosure. This method is used to compute "attention" results in multiple parts of a transformer architecture. For example, the QKV attention method is used for the self attention modules 602/620 and cross attention module 630 in FIG. 6.
The inputs Q 700, K 701, and V 702 are data in the format of matrix or tensors, that are used to compute the "attention" weightings to give to neighboring tokens in a sequence. This method allows the transformer to understand relationships between tokens in a program statement or broader source code context.
In a cross attention module of an encoder-decoder transform architecture using this QKV method, the K and V values come from the encoder layers output. In a self attention module of an encoder layer, the K and V data comes from a prior encoder layer. In a self attention module of a decoder layer, whether in an encoder-decoder or decoder-only transformer architecture, the K and V data comes from a prior encoder layer. In many embodiments, the K and V data will come from a "KV cache" stored in memory, if already computed by a prior computation, using the well-known KV caching optimization. In a self attention block of the autoregressive decoding phase of the decoder stack, the KV cache should contain already-computed K and V data for every token in the output token sequence, except the current output token for which its predicted probability is being calculated.
MatMul 710 performs a matrix multiplication between Q 700 and K 701, without using V 702. The output results are passed into the Scale module 720 that reduces the size of the values. In many embodiments, the scale factor is division by the square root of the internal model dimension size, which is the length of the embedding vectors.
The computed output from the Scale module 720 is passed into the Masking module 730, which is an optional module that can be skipped in some methods. When activated, the masking prevents the attention computation from "lookahead" and limits computations for a token to tokens earlier in the token sequence.
In an encoder-decoder transformer architecture, masking is disabled in attention blocks used in an encoder layer, but enabled when used within attention blocks in a decoder layer. In a decoder-only transformer architecture, masking of lookahead tokens may be disabled in the "prefill" phase at the start, and then enabled when in the subsequent autoregressive decoding phase.
The output from the Scale module 720, or its input when disabled, is passed to the Softmax module 740. The Softmax module 740 functions as already described above in FIG. 5 and its description.
The final phase of the QKV computation is the MatMul block 750, which multiplies the intermediate computations, based on Q 700 and K 701, with matrix multiplication using the data from V 702. Hence, the final result of the QKV attention block uses data from its three inputs Q 700, and K 701, and V 702.
FIG. 8. Feed-Forward Network
FIG. 8 is a block diagram of a Feed-Forward Network (FFN) module, also known as a Multi-Layer Perceptron (MLP), in accordance with a number of embodiments of the present disclosure. The FFN components are heavy computation phases in the transformer engine execution. The basic architecture of the FFN involves sending the FFN input tensor data 800 to a first linear layer 810 (using the first set of FFN weights and biases 820), an activation function module 830, and then a second linear layer 840 (using the second set of FFN weights and biases 821). Finally, there is an addition module 850 using the data from the FFN input tensor 800 via residual connection 855.
Each linear layer comprises a matrix multiplication operation using the corresponding weight matrix, optionally followed by addition of a bias vector, where each linear layer has its own specific set of weights and biases stored in the LLM.
Residual connection 855 sends a copy of the input tensor data 800 to be used after the two linear layers in the addition module 850. The use of an added input via a residual connection has been shown to be advantageous in training models, and is also calculated during inference.
The addition module 850 adds the output of the second linear layer 840 to the original inputs to the FFN module, thus adding the inputs and preliminary outputs to create the final output of the FFN module. This arithmetic addition method uses element-wise tensor or matrix addition of each pair of values.
The FFN is one of the major sublayer components in the layers of encoders and decoders. The encoder FFN 604 and the decoder FFN 640 in FIG. 6 use this FFN architecture.
FIG. 9. Multi-Head Attention
FIG. 9 is a block diagram of a Multi-Head Attention (MHA) module, in accordance with a number of embodiments of the present disclosure. This MHA method is a well-known optimization to the QKV attention computations in FIG. 7 The use of a MHA architecture facilitates parallelization of the computations in an attention block, such as a self attention block or cross attention block. The computation is split across H different blocks called "attention heads." Parallelized computation allows faster execution on GPU hardware or software threads.
The Scaled Attention block 920 and the linear layers (910, 911, 912) perform attention computations via matrix/tensor multiplications in accordance with Q 902, K 901 and V 900 tensors, as shown in FIG. 7 and its description.
The concatenate block 930 merges the outputs of the H attention heads into a single tensor result. Another linear layer 940 is applied to finalize the QKV computations for attention using a matrix and bias data, similar to the MatMul block 750 in FIG. 7.
The output of this MHA block is to be a faster way to compute a result that is identical or near-identical to the output of a single attention computation, as shown in FIG. 7, if it were computed on the whole data without parallelization.
FIG. 10. Autoregressive Decoding
FIG. 10 is a flow-chart of a method for autoregressive decoding in a transformer, in accordance with a number of embodiments of the present disclosure. A full decoding cycle is the execution of the layers of the decoder stack 1010 (or fewer layers if an early exit triggered) so as to output a single token. An autoregressive transformer performs one cycle per output token, in sequential execution (i.e. not parallel execution), outputting one token at a time. At the end of each decoding cycle, the output module 1020 chooses a new output token, and this newly output token and its embeddings data is sent down the autoregressive pathway 1030, where it is added to the intermediate output 1000, to be used as input to the first decoder layer in the next full decoder cycle.
The details of the decoder layer stack 1010 are shown in FIG. 6. Similarly, not all details of the output module 1020 are shown, as they have already been examined in FIG. 5. The output module will also include an unembedding module, Softmax module, untokenizer module and a decoding algorithm module to choose the token, including the many well-known decoding algorithms.
In addition to forwarding the new token to be used autoregressively, the output module 1020 may convert the token to text, and add it to the output text 1040. With simple decoding algorithms such as greedy decoding, the text is output immediately. In more advanced decoding algorithms, such as beam search decoding, the text output is deferred until the decoding algorithm makes additional computations as to which token or token sequence to finally output.
FIG. 11. Early Exit
FIG. 11 is a flow-chart of a method for early exit optimization of a transformer, in accordance with a number of embodiments of the present disclosure. The early exit module will stop executing further layers of the decoder stack, if conditions are met, thereby avoiding much computation and improving efficiency. The early exit test 1140 makes the decision whether or not to exit processing at the current decoder layer. If the pathway is Yes 1141, then further decoder layers are not executed, and the decoding module 1150 performs the end-stage of a full decoding cycle. If the pathway chosen is No 1142, then processing continues as usual to the next layer in the decoder stack.
The input to the early exit module is the output of a decoder layer in an embeddings data format. This embeddings data is converted to token probabilities ("logits") using the unembedding module 1110, which converts to non-normalized internal numeric values, and then the Softmax module 1130, which converts to token probabilities. The output of Softmax is logits that are normalized with each value within the range [0,1], inclusive, and logit values properly sum to one. The details of the unembedding module 1110 and Softmax module 1130 have already been described in FIG. 5 and associated discussion.
There are several embodiments of methods for the early exit test 1140 in the prior art, including several methods based on: (a) no token probabilities, or (b) computation of the probabilities of the tokens. For example, no token probabilities are used to exit after executing a fixed number of layers, or after a fixed percentage of layers, such as exiting after 50% of layers. As an alternative example, the token probabilities (or at least, their unembedding values) may be computed so as to find the token with the highest probability.
Note that early exit criteria based on the maximum of the token probabilities, or also the second highest or top-k highest values, could be optimized to avoid the Softmax computation, by using the maximum tests on the pre-Softmax values after the unembedding computation. The maximum pre-Softmax value token will also have the maximum Softmax-computed probability, as will the second-highest, and so on, because the exponentiation function used in Softmax is a monotonically increasing mathematical function.
Some simple types of early exit decision criteria do not use the probabilities of all tokens. For example, early exiting after a fixed number of layers is a simple comparison between the layer count and a fixed constant, without considering any token probabilities. Another variant would be two fixed layer counts, with different values for the encoder stack versus the decoder stack in an encoder-decoder transformer architecture, or differing for the prefill phase versus the decoding phase in a decoder-only transformer. Note that the early exit test is also trivial at the final layer of the decoder stack, as further processing of decoder layers cannot occur in any case.
If the early exit decision criteria is a simplistic method, such as executing after a fixed number of layers, then the unembedding module 1110 and Softmax module 1130 are not used to evaluate the early exit test 1140, but will be subsequently used in the decoding module 1150 if an early exit of layers is triggered.
The decoding module 1150 is executed if early exit of layers is triggered by the Yes pathway 1141. This decoding module includes various modules already described in earlier figures, including a decoding algorithm, untokenization, and an autoregressive token pathway. If the unembedding module 1110 and Softmax module 1130 have already been computed prior to evaluating the early exit test 1140, then the decoding module 1150 may not re-compute the unembedding or Softmax computations because these have already been performed in the early exit pathway.
If the early exit test 1140 fails, then the No pathway 1142 is executed, which continues execution of the next decoder layer 1145. If the early exit test 1130 has decision criteria that only consider the current layer of logits, then the outputs of the unembedding module 1110 and Softmax module 1130, if any, are discarded, which is an inefficiency. However, these values may be retained in memory for use in a future test by the early exit test module 1140, if the early exit decision criteria involve probabilities from prior layers. If the early exit criteria are simplistic tests not involving logits, such as a fixed number of layers, then there are no values computed by the unembedding module 1110 and Softmax module 1130, and nothing needs to be stored.
The diagrams in FIG. 12 through FIG. 16 show novel aspects of the methods and apparatuses in embodiments of the presently disclosed invention, including an edit decoding method, a combined edit decoding and early exit method, and a further optimized method of early exit based on the current input token.
FIG. 12. Edit Decoding
FIG. 12 is a flow-chart of a method for edit decoding using a transformer for source code checking, in accordance with a number of embodiments of the present disclosure. The edit decoding algorithm is a novel method of performing source code checking with improved efficiency, along with a reduction in over-corrections and over-creativity, by focusing on the input program text versus the other predictions of the LLM.
Transformer inference phase module 1250 represents a full transformer decoding cycle to generate the next output token, which may be embodied as an encoder-decoder transformer architecture or a decoder-only transformer architecture. The details of the transformer architecture, including the encoder stack, decoder stack, and autoregressive decoding pathway, have been described in FIG. 6 and FIG. 10, along with the associated description.
The current input token module 1265 computes the current input token value in the input token sequences, along with its predicted probability, as computed from the logits after a full decoding cycle, including after an early-exited full decoding cycle, for use in the edit decoding method. The idea is to accept the input token if it matches the predicted token value with the highest probability from a full decoding cycle, or at least, if the current input token has an acceptable probability, even if it is not the highest. In this way, the input text is prioritized over alternative outputs from the transformer engine, unless the acceptance computation rejects the current input token, so as to reduce or avoid excessive creativity or over-correction problems that are common when LLMs are used to perform source code checking.
The current input token module 1265 uses the logits, which are token probabilities in the range [0,1] inclusive, as computed from the internal embeddings data via the unembedding module 1255 and then normalized by the Softmax module 1260. The index of the current input token for the input text is maintained by the edit decoding algorithm, and the numeric integer value of the current input token can be efficiently extracted as an array lookup into the input token sequence using this index offset. Given the integer value of the input token and the logits array of token probabilities from Softmax 1260, the probability of the current input token can be computed by an efficient array lookup in the logits array using the token value as the array index.
The evaluate token and synchronize module 1270 is part of the edit decoding method, where the edit decoding method decides whether to accept or reject the current input token versus whatever token the model is suggesting, and then attempts to synchronize the input and output sequences, if it becomes unsynchronized. Full details of the evaluate token and synchronize module 1270, including its acceptance testing and handling of source code corrections, are shown in more detail in FIG. 14 and its associated description.
Several modules in FIG. 12 have already been shown in other prior figures and their descriptions. The details of the input text 1200 and input module 1210 have been described in FIG. 4. The details of the unembedding module 1255 and the Softmax module 1260 have been described in FIG. 5 and the associated description of the output module. The details of the output token module 1275, including the output of text, and the autoregressive decoding pathway, have been described in FIG. 5 and FIG. 10.
The more tokens test 1220 and end module 1230 decide when to complete the source code checking analysis using edit decoding, which usually occurs after the full input text has been analyzed. The end-of-sequence handling can be performed in several ways. The simplest method is simply to terminate the algorithm at the end module 1230 when there are no more input tokens to process, as shown by the more tokens test 1220. However, this does not allow the output to be longer than the input, thus disallowing some corrections involving text insertion, or truncating the output in some cases. A more nuanced method as an alternative embodiment would be to detect the end-of-sequence, and then still allow the transformer to output a few more tokens, according to the other well-known methods of detecting output sequence termination points, such as: (a) maximum token length configurations, or (b) stop tokens. Similarly, if the model predicts a stop token with high probability, the output should support terminating early, so that source code corrections that shorten the text have a clean ending sequence. These termination methods are well-known in the prior art and can be readily applied here.
FIG. 13. Token-Based Early Exit
FIG. 13 is a flow-chart of an improved method for early exit, extended by current input token decision optimization, in accordance with a number of embodiments of the present disclosure. Prior art methods of early exit do not take advantage of the extra information available from the input context tokens, which is particularly true in source code checking where the input text is a program being edited. Basing the early exit decision on both the computed logits and the probability of the input text tokens allows for: (a) greater efficiency by early exiting the decoder stack more often and at lower layers, thereby skipping more layers of computation in total, and (b) improved accuracy in corrections by reducing over-creativity and over-correction problems.
Much of FIG. 13 is similar to FIG. 11, but with an extra current input token testing module 1340. This improved early exit module has two exit tests: (a) the new current input token test 1340, and (b) the general early exit test module 1343, with decision logic based on the probabilities of the tokens. If either of these tests succeed, the layers exit early and results are sent to the decoding module 1350.
The current input token test 1340 determines the current input token using its tracked index position and the input token sequence, which is calculated once during tokenization from the input text 1320. If the early exit test using the current input test succeeds, execution follows the Yes path 1341 with early exiting triggered and the decoding module 1350 will finalize the output of the decoding cycle.
The current input token test 1340 is placed before the early exit all tokens text 1343. If the current input token test 1340 fails, execution follows the No path 1342 and a follow-up general all tokens early exit test 1343 is performed.
Various methods of using the current input token and its probability in the current input token test 1340 include: (a) a threshold probability is exceeded by the current input token (e.g., the current input token has a probability at 20% or more); (b) current input token ranking is below a ranking threshold based on the inverse of a threshold probability (e.g., the current input token's ranking is less than 5, which is the inverse of 20%); (c) current input token has the maximum predicted probability; (d) current input token is one of the top-k predicted output tokens in terms of relative probabilities (e.g., k=2 means the token has maximal or second-highest probability); or (e) a combination thereof. An example of a combination would be to use the current input token if it has maximum predicted probability, and also exceeds a lower-bound 20% probability threshold.
The decoding module 1350 includes various modules already described in earlier figures, including a decoding algorithm, untokenization, and an autoregressive token pathway. However, it does not calculate its own unembedding or Softmax outputs if these have already been calculated in the early exit pathway.
The all-tokens early exit module 1343 has already been described, including versions requiring all logit probabilities and simpler versions not requiring any probabilities. The all-tokens early exit module 1343 may have any or all of the features described for the early exit decision module 1140 in FIG. 11.
Another embodiment of this method is to use different acceptance calculations at the current input token test 1340 for different decoder layers. The predictions of many models become more accurate after each layer. Early layers tend to roughly compute the general probabilities, middle layers are sorting out the hierarchy and longer context relevance, and the final layers tend to finesse between various acceptable candidates. Furthermore, so-called "easy" tokens tend to be chosen early, whereas "hard" tokens don't get chosen until later layers. Hence, it would be appropriate to make the criteria more difficult to pass in the early layers, but easier in the higher layers.
This use of layer-specific criteria at the current input token test 1340 is both efficient and accurate, by allowing early exit quickly in a lower layer if the prediction is "easy" and has a high probability in early layers, whereas "difficult" tokens would be rejected until later layers, but could still exit earlier in the middle or final layers. For example, three threshold percentages could be used to test the current input token probability, representing thresholds for the early, middle, and later layers of the decoder stack. In the general case, completely different criteria with different thresholds could be used for every layer.
Another further embodiment of this method is to extend the current input token test 1340 to use early exit acceptance criteria based on input tokens that apply to multiple full decoding cycles along the lengthwise dimension of the token sequence. For example, in an extension to edit decoding, the acceptance criteria for the current input token could also consider in its calculations the probability or ranking of the previous input token. As another example, the criteria could include whether or not the prior input token was accepted, or was corrected by an editing change.
It is efficient to put the current input token test 1340 before the all-tokens early exit test 1343 because: (a) it is a "common case first" optimization because it is more likely to succeed at an earlier layer; and (b) it is a "simple case first" optimization if the current input token test 1340 does not use any linear-complexity operations, such as maximum or top-k calculations, such as where the test is based on comparing the probability of the current input token against a fixed threshold value, which can be computed in constant time complexity.
An optimized version of the current input token exit test 1340 is available where it exits early if the current input token is also the highest-probability predicted token, or in the highest top-k tokens. For these tests, it is possible to avoid executing the Softmax module 1330 and analyze the output values of the unembedding module 1310. The calculated numeric values from the unembedding module 1310 are log-scale values for each token, which are of unclear significance versus exact probabilities, but are nevertheless indicative of relative magnitudes because exponentiation is a monotonically increasing mathematical function. Hence, in this circumstance, the current input token exit test 1340 could compute either the maximum of the unembedding values, or the top-k of such values, in order to decide on the current input token early exit test 1340 without needing Softmax calculations. Although efficient for a maximum or top-k early exit decision test against the current input token, this optimization does not allow a threshold test against the actual probability of the current input token.
A minor optimization to this method is computing the input token value at the start of each decoding cycle, or at the very first early exit decision. This avoids the re-calculation of this value at every current input token test 1340 at different layers within the same decoding cycle. However, the probability or ranking of the current input token is re-calculated at every layer where there is an early exit test.
FIG. 14. Edit Decoding Evaluation Details
FIG. 14 is a flow-chart of a method of evaluation and synchronization as part of edit decoding for using a transformer for source code checking, in accordance with a number of embodiments of the present disclosure. The details of the edit decoding method shown in FIG. 14 demonstrate the method to handle unchanged tokens (i.e., acceptance of the current input token without a correction), and the three main types of source code corrections: (a) deleted tokens, (b) inserted tokens, and (c) changed tokens.
Unchanged tokens are those where the output token predicted by the model matches the current input token in the token acceptance module 1470. Another acceptance method is to also allow cases where the current input token is not the maximal probability token predicted by the model, but is nevertheless acceptable. For example, the current input token may be acceptable if its probability is high enough (e.g., 20%) or if its ranking is in the top few tokens (e.g., top-10 ranking). In this way, the current input token overrides the best model prediction, so as to reduce over-corrections, and keep the source code changes close to the original text. At the start and early tokens of the input is an area where the input tokens should be accepted, unless they are below a very low probability (e.g., 0.5%).
The Yes pathway 1471 from acceptance test 1470 indicates that the current input token has been accepted for output. As discussed, depending on the chosen acceptance criteria in the embodiment, this may mean that the transformer's predicted probability for the input token is the highest, or it may mean that the input token has an acceptably high probability above a threshold, or within a top-N decision of the probabilities of all tokens, even if there may be an alternative suggested token in the logits with a higher probability, or possibly even more than one such higher probability token.
The No pathway 1472 from the acceptance test 1470 indicates that the current input token is not accepted for output, and the transformer engine predicts a better token. Hence, the new token suggestion is a source code correction, which may be a deletion, insertion, or changed token.
The deleted token test 1475 aims to determine whether or not the calculated correction involves deleting a token from the input token sequence. A source code correction involving deleting a token can be detected if the model suggests a token that equals the second token in the input token sequence. Similarly, a source code correction where two tokens may be deleted can be detected if the output token matches the third input token. If a stop token is detected, and there are still input tokens, then a deletion correction can be detected, but processing will stop anyway.
The Yes pathway 1477 indicates that a deletion edit has been detected, whereby a token is deleted from the input text. The No pathway 1476 indicates that the correction is not a deletion, and continues on to the added token test 1480, to distinguish between insertions and changes.
The synchronize deletion module 1478 attempts to re-synchronize the input token sequence with the output token sequence when a deletion edit has been detected. If the output token is ahead by one or two positions in the input text, then the input text can be re-synchronized at that position. If not, then the decoding algorithm may enter an unsynchronized mode.
The added token test 1480 attempts to detect a source code correction involving insertion of new tokens into the input text. The synchronize insertion module 1484 attempts to re-synchronize the input token sequence with the output token sequence when an insertion edit has been detected. An insertion correction cannot be immediately detected after the output of the first inserted token, but is deferred until at least one other token has been emitted. When the next output token is equal to the current input token (which is then the prior input token), an insertion can be detected, and the input can be re-synchronized to the prior input token position. Similarly, an insertion of two new tokens can be detected after two further decoding cycles, when the new output token equals the pre-prior token (two tokens earlier) and the input sequence can be re-synchronized back by two.
The change token module 1485 handles the case where a token has been changed to a different token (e.g., replacing a program token in the text), but where there are neither more nor fewer tokens. As with insertion, this cannot be detected immediately at the current output token, and re-synchronization awaits another full decoding cycle. If the newly output token is then equal to the next input token, rather than the current input token, then the edit is a change correction of one token.
When this change correction is detected in the next decoding cycle, it will actually be detected as the current output token equaling the current input token, but with the prior output token not equal to the prior input token. Similarly, a change to two tokens can be detected after two full decoding cycles, whereby the third output token equals the third input token. Another issue at the end of processing occurs if the output text is the stop token, and this matches the end of the input token sequence.
The change token module 1485 does not use a synchronization method when a change of one or two tokens is detected, when there is no difference in the length of the input and output token sequences. The method can continue on the subsequent tokens of the input and output.
As discussed above, the logic of the inserted or added token test 1480 is deferred until after at least one further decoding cycle. The Yes pathway 482 indicates that an inserted token has been detected, and this can be processed and post-insertion re-synchronization can occur as discussed above. Similarly, if a change correction is detected, then post-change re-synchronization can occur, which doesn't alter the positioning, but can at least turn off the unsynchronized mode if the token sequences are matching again. Until there is extra tokens from one or two decoding cycles, the decoding algorithm enters an unsynchronized mode that can be recovered when either a change or insertion is confirmed. If neither a change nor an insertion is detected in future tokens, the worst case is the decoding algorithm remains permanently in the unsynchronized mode, and simply outputs the model's predicted output tokens.
There are several details of circumstances to be handled by the token acceptance module 1470 including: (a) the first token, (b) unsynchronized tokens, and (c) long outputs.
The first token in the input sequence is handled specially and is accepted. A probability cannot be calculated when there are zero prior tokens in edit decoding.
If synchronization has been lost earlier in the sequence, and the input and output token sequences are out of synchronization, then all subsequent tokens are accepted until re-synchronization occurs. Re-synchronization can be detected when the input token has an adequate probability or otherwise meets the acceptance threshold tests. Simple re-synchronization can occur by searching the input token sequence for an output token. More accurate re-synchronization can be achieved by searching the input token sequence for two or more output tokens (e.g., the current output token and the prior output token). Extensions are readily apparent in that greater accuracy is possible by searching for more than two tokens during re-synchronization, and also more accurate handling detection of insertions, deletions, or changes that involve more than two tokens.
If the transformer creates an output longer than the input text, such as by making insertions to fix errors, then there is no matching input token to compare because the input text is shorter. In this case, all of the subsequent output tokens are accepted and output, until the model outputs a stop token or another standard termination condition occurs.
FIG. 15. Edit Decoding and Early Exit
FIG. 15 is a flow-chart of a method for integrating edit decoding and early exit in a transformer, in accordance with a number of embodiments of the present disclosure. FIG. 15 is an extension of the novel edit decoding method (FIG. 12) with an early exit module 1555, including various possible embodiments of prior art methods for early exit methods, and the details of the early exit method were shown in FIG. 11. The early exit module 1555 can send the output to the edit decoding module 1570 if it decides to early exit. If no early exit is triggered, then the edit decoding module will get the output results after all transformer layers 1550 have executed.
Various modules in FIG. 15 are identical to the analogous modules in FIG. 12 with the same suffix numbers. The edit decoding module 1570 represents several modules from FIG. 12. The input text 1500 and the input module 1510 have already been discussed in FIG. 4.
The output of the edit decoding module 1570 is a token, and its associated internal embeddings data, which is sent to the output token module 1575. The output module 1575 may convert the token to text string to emit as output text, and may also send the token and its data to the autoregressive pathway where it returns to the "more tokens" test 1520. The "more tokens" test 1520 pathway for Yes 1522 continues the next full decoding cycle, if there are more input tokens and a stop token has not been already detected, whereas the No pathway 1521 terminates further processing of the input text at the end module 1530. Further details of the output module 1575 and the autoregressive pathway have been discussed in FIG. 5 and FIG. 10, and the associated descriptions.
FIG. 16. Edit Decoding and Token-Based Early Exit
FIG. 16 is a flow-chart of a method for integrating edit decoding and early exit optimized with current input token decision logic, in accordance with a number of embodiments of the present disclosure. FIG. 16 shows the addition of the current input token decision logic into the early exit module of the system in FIG. 15, which shows a system combining edit decoding and early exit. This shows all of the main novel components of the present disclosure used together as one possible embodiment. Many of the components in FIG. 16 are analogous to those with similar suffix numbers in FIG. 15. The current input token decision logic module 1665 offers a second, and more efficient, way to decide to early exit from the layers in the decoder 1650. This decision logic method using the current input token is shown in detail in FIG. 13.
Summary
For the purposes of interpretation of the description herein, the designatory term "a number of" means one or more, a "plurality" means two or more, and a numeric designation such as "N" of an element means a number of such elements. Where the same designator has been applied to different elements, this does not imply that they must have the same number.
The foregoing description of the embodiments of the invention has been presented for the purpose of illustration and is not intended to be exhaustive or to limit the invention to the precise forms described herein. Persons skilled in the relevant art can appreciate that many modifications and variations are possible in light of the above disclosure. Elements shown in the various embodiments herein may be added, modified, exchanged, and/or eliminated so as to provide a number of additional embodiments of the present disclosure. Adaptations, variations and/or alternative methods of implementing elements in the disclosure that produce the same results can be substituted for the specific embodiments herein.
Numerous specific features of the embodiments have been disclosed in the descriptions and drawings, in order to provide context for a thorough understanding. However, some well-known or conventional details are not described in order to provide a concise discussion of embodiments disclosed herein.
Various features are grouped together in a single embodiment in the descriptions herein for the purposes of streamlining the disclosure. This manner of disclosure is not to be interpreted as reflecting an intention that the disclosed embodiments have to use more features than are expressly recited in each claim. In particular, many embodiments have been described in relation to source code checking use cases, but some methods have broader applicability and the claims should not be construed as implying any limitation to any specific use case unless expressly so stated.
Some portions of this description describe the embodiments of the invention in terms of algorithms and symbolic representations of operations on information. These algorithmic descriptions and representations are commonly used by those skilled in the data processing arts to convey the substance of their work effectively to others skilled in the art. These operations, while described functionally, computationally, or logically, are understood to be implemented by computer programs or equivalent electrical circuits, microcode, or the like. Furthermore, it has also proven convenient at times, to refer to these arrangements of operations as modules, without loss of generality. The described operations and their associated modules may be embodied in software, firmware, hardware, or any combinations thereof.
Any of the steps, operations, or processes described herein may be performed or implemented with one or more hardware or software modules, alone or in combination with other devices. In one embodiment, a software module is implemented with a computer program product comprising a computer-readable medium containing computer program code, which can be executed by a computer processor for performing any or all of the steps, operations, or processes described.
Embodiments of the invention may also relate to an apparatus for performing the operations herein. This apparatus may be specially constructed for the required purposes, and/or it may comprise a general-purpose computing device selectively activated or reconfigured by a computer program stored in the computer. Such a computer program may be stored in a non-transitory, tangible computer readable storage medium , or any type of media suitable for storing electronic instructions, which may be coupled to a computer device bus. Furthermore , any computing systems referred to in the specification may include a single processor or may be architectures employing multiple processor designs for increased computing capability.
Embodiments disclosed herein are not described with reference to any particular programming language. A variety of programming languages may be used to implement the methods and apparatuses.
Although embodiments disclosed above may described with some sequential steps, some such operations may be performed in a different order, or with some steps performed in parallel by software or hardware.
Embodiments of the invention may also relate to a product that is produced by a computing process described herein. Such a product may comprise information resulting from a computing process, where the information is stored on a non transitory, tangible computer readable storage medium and may include any embodiment of a computer program product or other data combination described herein.
Finally , the language used in the specification has been principally selected for readability and instructional purposes, and it may not have been selected to delineate or circumscribe the inventive subject matter. It is therefore intended that the scope of the invention be limited not by this detailed description, but rather by any claims that issue on an application based hereon. Each of the following claims are hereby incorporated into the detailed description as a separate embodiment. Thus, the disclosure of the embodiments of the invention is intended to be illustrative, but not limiting, of the scope of the invention, which is set forth in the following claims.
CLAIMS
What is claimed is:
-
A method for performing source code checking,
comprising the steps of:
(a) converting input text into a reference token sequence;
(b) performing a full decoding cycle of a transformer system to generate logits;
(c) determining the current reference token in the reference token sequence;
(d) determining the predicted probability of the current reference token;
(e) deciding whether to emit the reference token or one of the other tokens;
(f) detecting whether the result is an acceptance, a change, an insertion, or a deletion; and
(g) synchronizing the reference token sequence with the output token sequence. - The method of Claim 1, wherein the full decoding cycle uses an early exit method at one or more layers.
-
The method of Claim 1, wherein:
(a) the full decoding cycle uses an early exit method at one or more layers; and
(b) the early exit method uses the current reference token in deciding whether to exit. -
The method of Claim 1, wherein:
(a) the full decoding cycle uses an early exit method at one or more layers; and
(b) the early exit method uses more than one token from the reference token sequence in deciding whether to exit. - The method of Claim 1, wherein the transformer system comprises an encoder-decoder transformer architecture.
- The method of Claim 1, wherein the transformer system comprises a decoder-only transformer architecture.
-
A method for performing inference in a neural network system,
comprising the steps of:
(a) calculating a reference token sequence;
(b) performing a layer computation of a neural network model;
(c) calculating information about output tokens from the layer computation;
(d) determining a current reference token from the reference token sequence;
(e) performing a comparison of the reference token information to the output token information; and
(f) deciding whether or not to skip further layers based on the comparison. - The method of Claim 7, wherein the neural network system comprises an encoder-only transformer architecture.
- The method of Claim 7, wherein the neural network system comprises a decoder-only transformer architecture.
-
The method of Claim 7, wherein:
(a) the neural network system comprises a decoder-only transformer architecture; and
(b) the layer computation occurs in the prefill phase. -
The method of Claim 7, wherein:
(a) the neural network system comprises a decoder-only transformer architecture; and
(b) the layer computation occurs in the decoding phase. - The method of Claim 7, wherein the neural network system comprises an encoder-decoder transformer architecture.
-
The method of Claim 7, wherein:
(a) the neural network system comprises an encoder-decoder transformer architecture; and
(b) the layer computation occurs in an encoder layer. -
The method of Claim 7, wherein:
(a) the neural network system comprises an encoder-decoder transformer architecture; and
(b) the layer computation occurs in a decoder layer. - The method of Claim 7, wherein the comparison considers the relative ranking of the current reference token and output tokens.
- The method of Claim 7, wherein the comparison considers the predicted probabilities of the current reference token and output tokens.
- The method of Claim 7, wherein the comparison involves comparing the predicted probability of the current reference token with a threshold.
- The method of Claim 7, wherein the comparison involves comparing the relative ranking of the current reference token with a threshold.
- The method of Claim 7, wherein the inference is performed for source code checking.
- The method of Claim 7, wherein the inference is performed for on-device inference.
- The method of Claim 7, wherein the inference is performed on a cloud system.
DRAWINGS
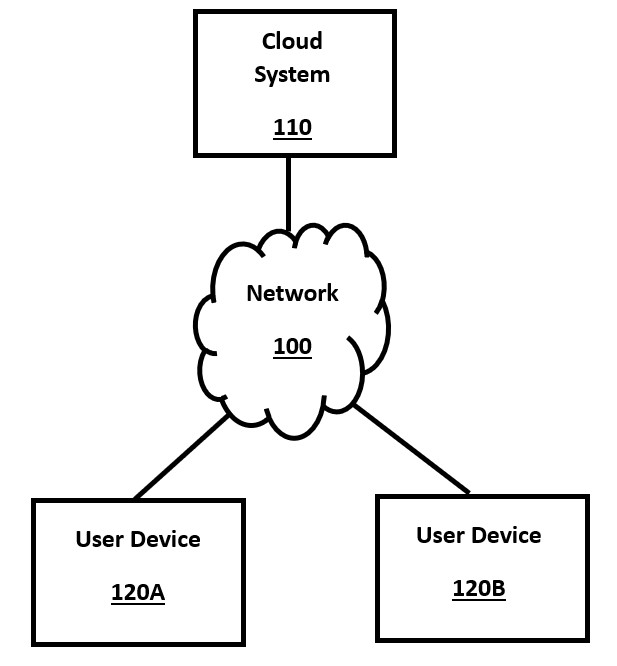
FIG. 1
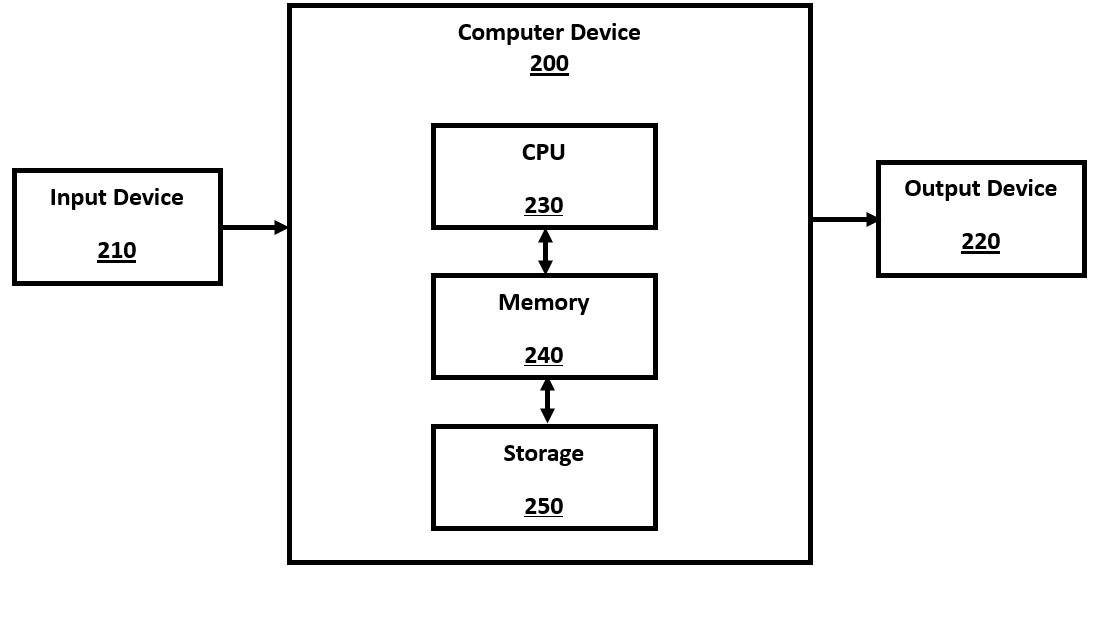
FIG. 2
![]()
FIG. 3
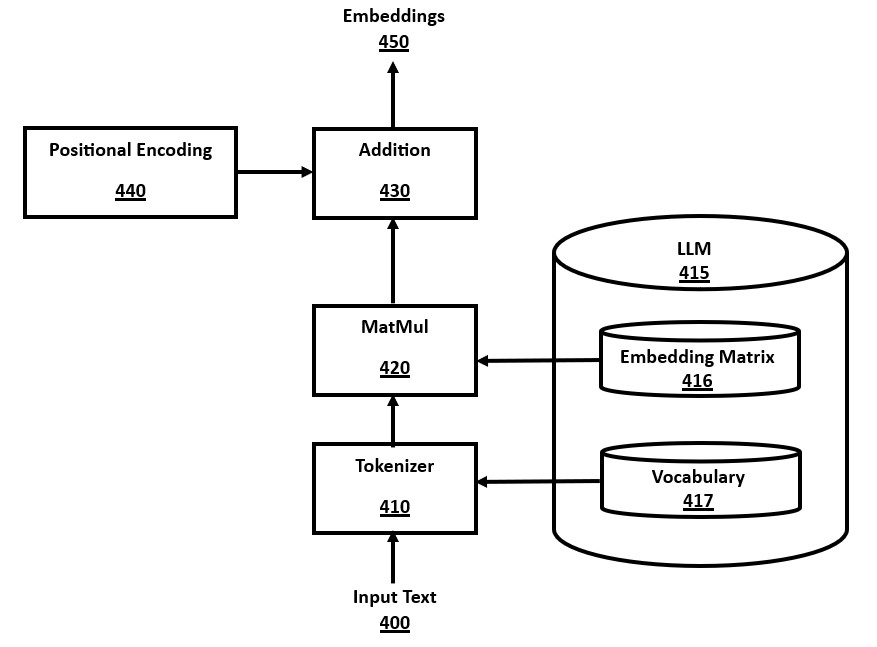
FIG. 4
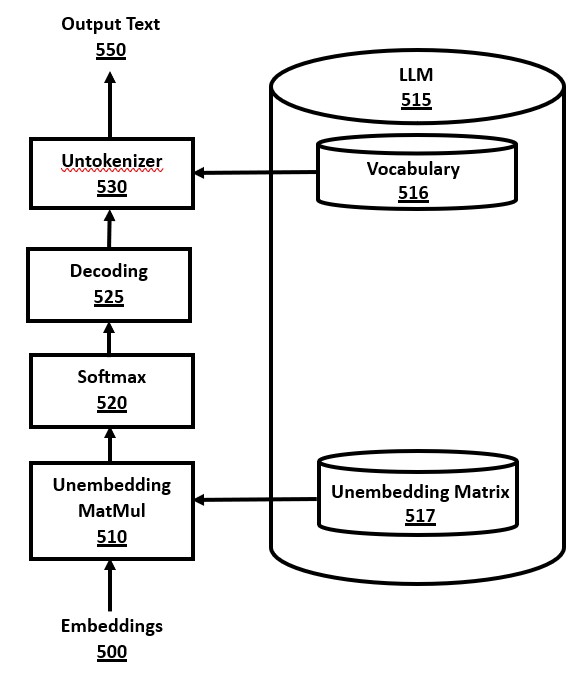
FIG. 5
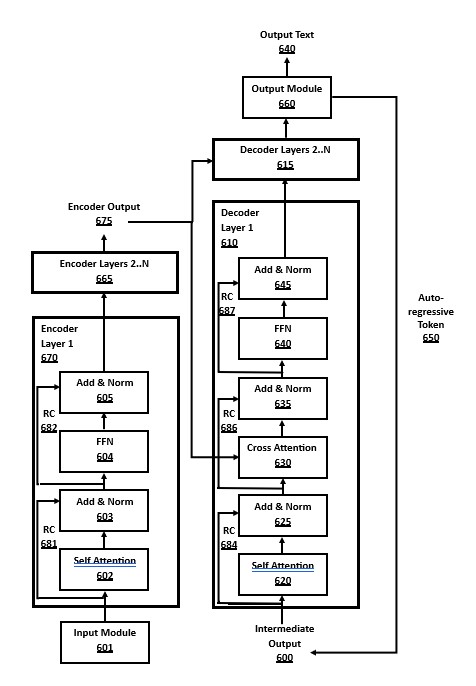
FIG. 6
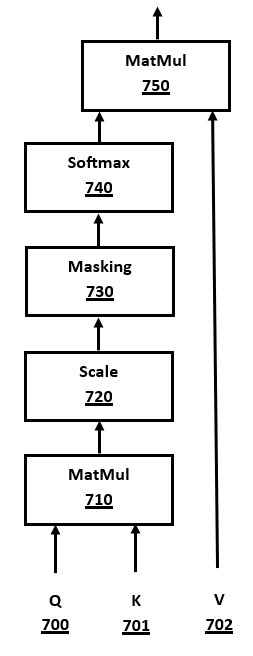
FIG. 7
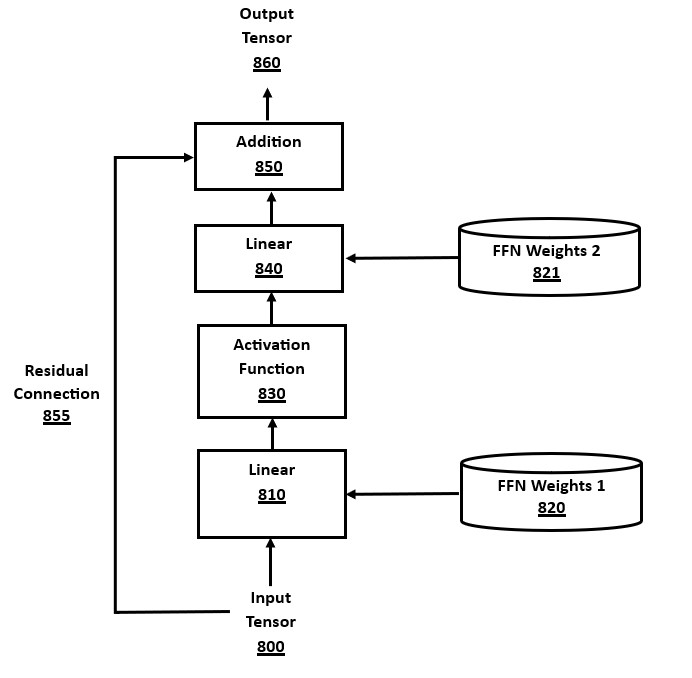
FIG. 8
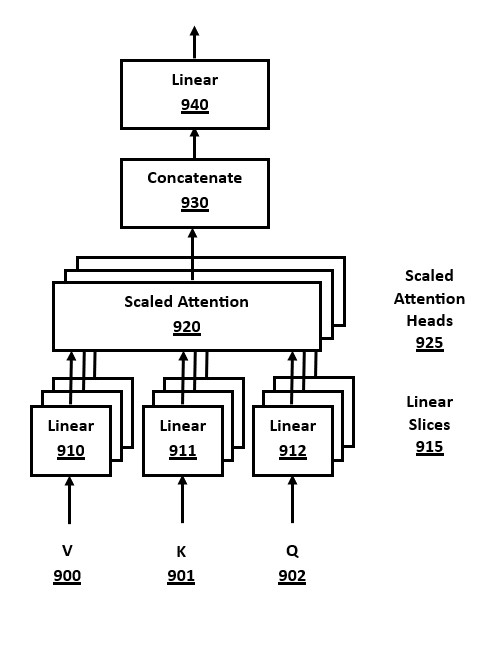
FIG. 9
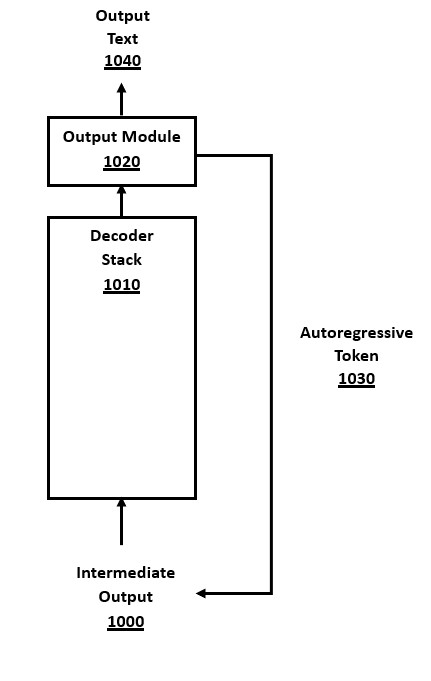
FIG. 10
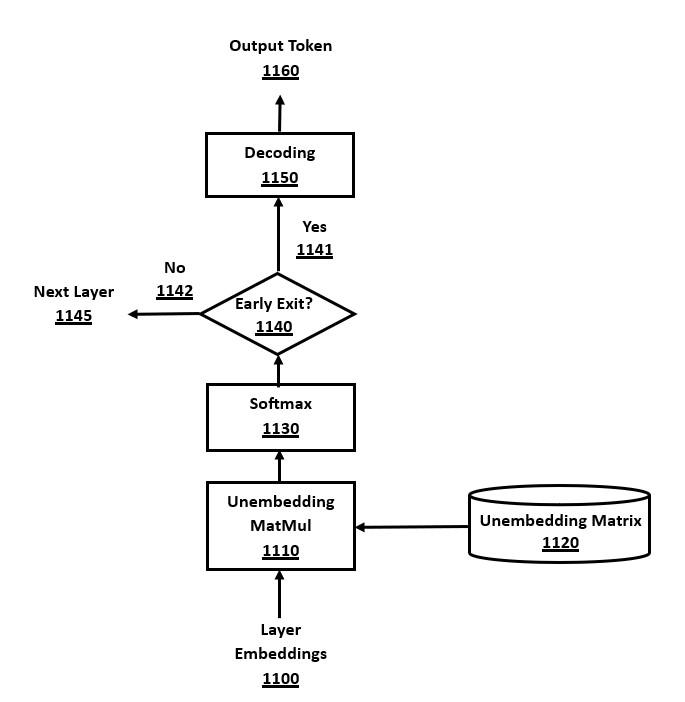
FIG. 11
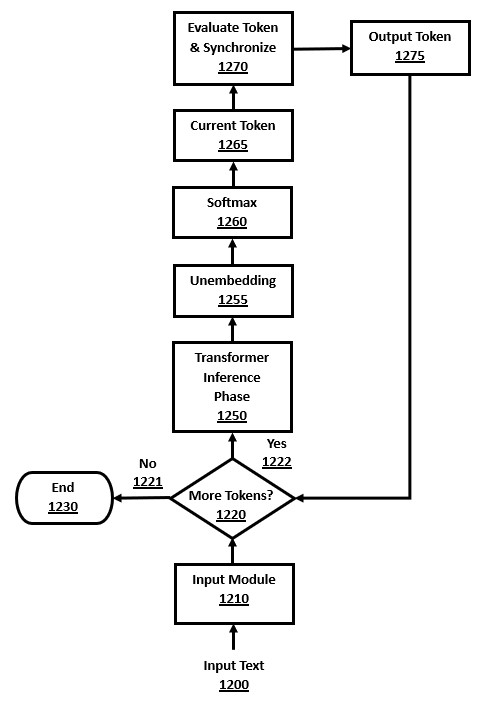
FIG. 12
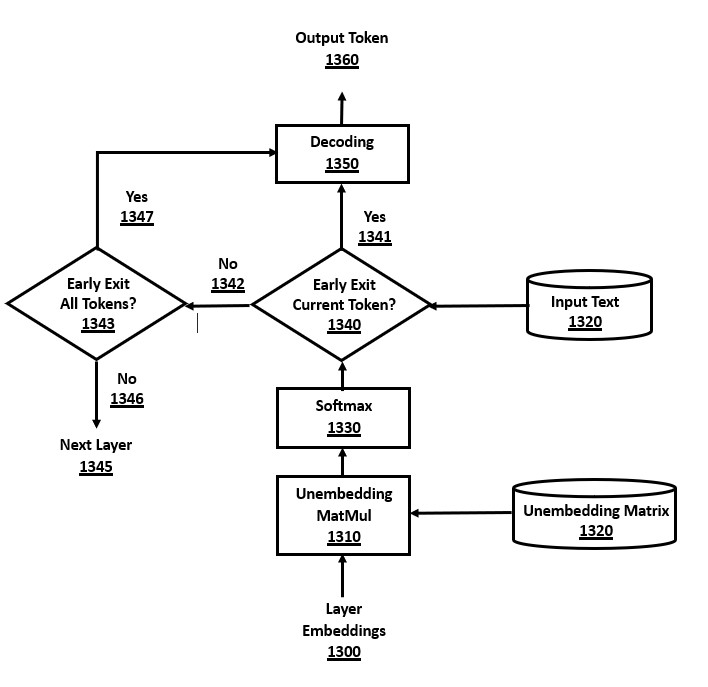
FIG. 13
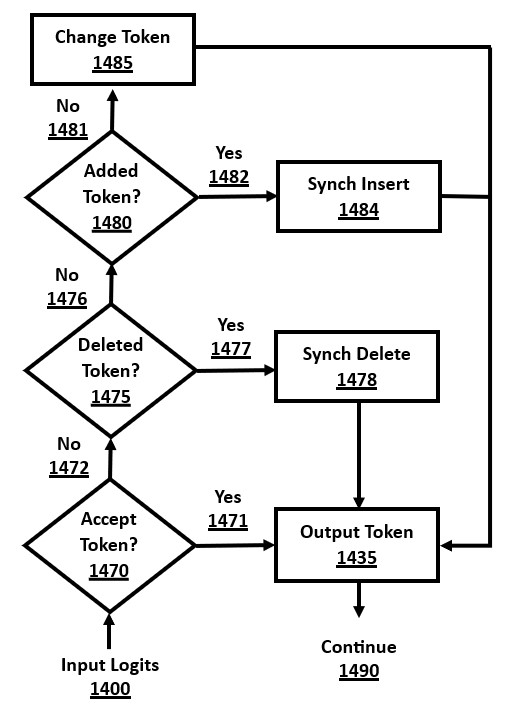
FIG. 14
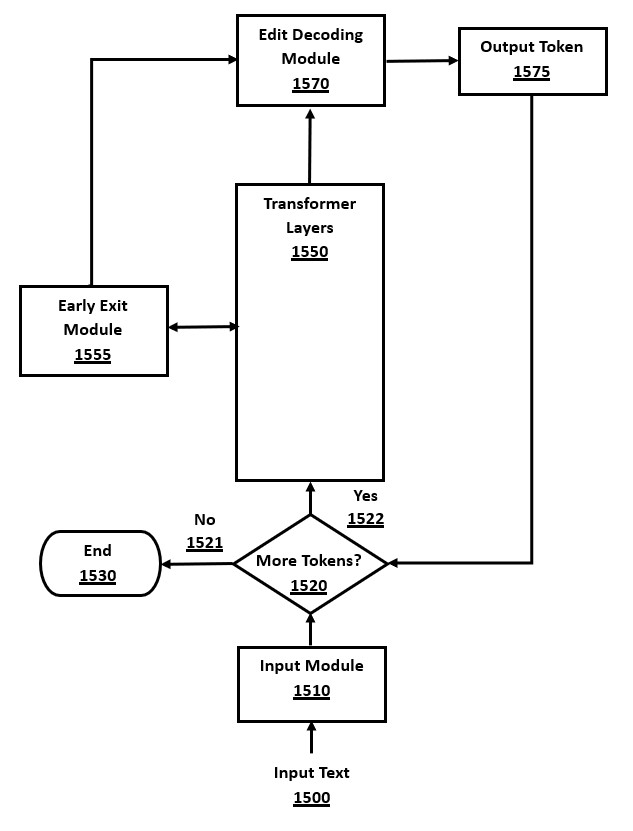
FIG. 15
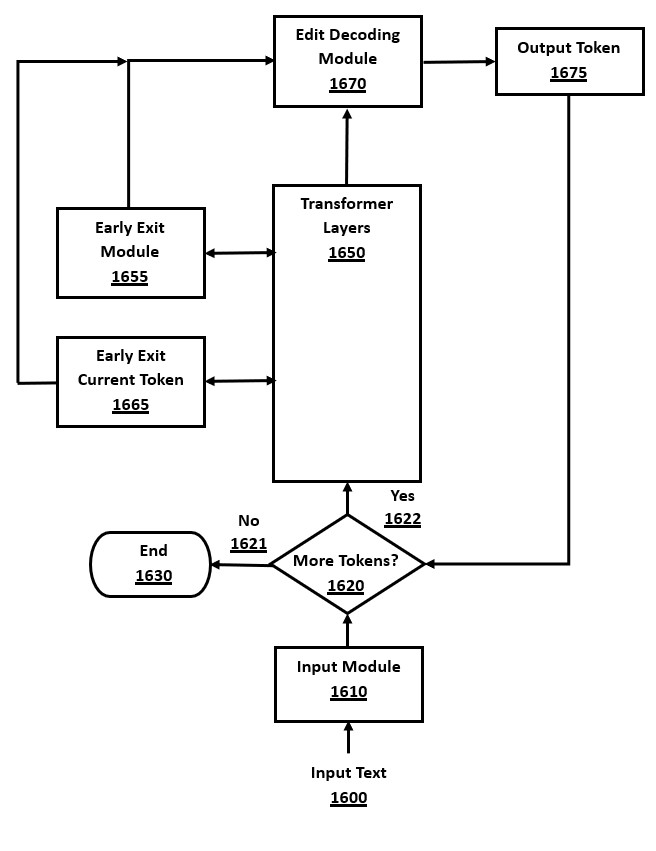
FIG. 16