Aussie AI
12. ’Rithmetic
-
Book Excerpt from "The Sweetest Lesson: Your Brain vs AI"
-
by David Spuler, Ph.D.
12. ’Rithmetic
“Math skills are a powerful indicator of future success.”
— Bill Gates.
Everyone Loves Math
Humans are great at arithmetic! Right from birth, we can add up 10-digit numbers in our heads, without even using our fingers and toes.
Umm, no.
Weirdly, AI is bad at arithmetic, too! Maybe it’s not so weird, as we’ve been discussing the parallels between brains and LLMs, but it definitely seems funny to me. Surely, computers can do basic sums very easily?
Yes, indeed. Your average laptop computer is running a CPU that has a clock speed of about 1 or 2 Gigahertz, so, let’s say it’s about 2 billion operations per second. And the most basic computer instructions are addition and multiplication operations. In fact, those are the simplest of operations, but there are all sorts of other maths stuff, too.
If you have an older laptop, it can only do “32-bit” operations, which is numbers up to about 2.7 billion, which are at most 10-digit numbers. But most modern laptops are now using “64-bit” CPUs, which allows up to 19-digit numbers. To help you win Trivial Pursuit next Saturday at your AI club meet, note that a trillion has a one followed by 12 zeros for a total of 13 digits, a quadrillion has 16 digits, and a quintillion has 19 digits. So, your basic laptop from Best Buy that you can buy on a credit card for less than the cost of a pet parrot, can do perfect arithmetic in massive numbers up to quintillions using at least 19 digits, and do so with 100% accuracy, over and over, billions of times per second.
An LLM can’t.
Every LLM is great at detecting patterns and knows about words. In fact, it usually treats a number as a word, and a 10-digit number will likely be 10 words, one digit each. So, the LLM will have seen “sentences” like “1 + 1 = 2” in its training, so it’ll nail those ones. Unfortunately, it’s expensive to train it to recognize all the different “words” up to a billion, let alone a quintillion.
Infinity is a little problematic.
If you’re thinking that it’s smart enough to figure it out from the other sums it’s been trained on, well, I beg to differ. LLMs have been historically poor at “generalization” of patterns. For example, if it knows the pattern “1+1=2” that doesn’t mean that it knows the pattern “1,000,000,000+1,000,000,000=2,000,000,000” at all, unless it’s seen that exact pattern in some other training document. A human child does this extrapolation of patterns innately, but your average multi-billion-dollar LLM struggles at this very hard stuff.
Okay, before every CEO of an AI company sends me a nasty cease-and-desist letter pointing out that their trillion-parameter LLM can do sums just fine: yes, they’ve figured it out now. But for years, LLMs were bad at basic arithmetic, let alone more advanced math, and there were research papers published all about the problems with basic arithmetic and complex math. So many.
And, honestly, LLMs are still poor at arithmetic, but there’s a couple of workarounds. One is “reasoning models” that can do multiple steps to solve a problem, which we discussed in a separate chapter. However, although I don’t know for sure how it does it in the big LLMs, I’m betting it’s the second one:
Tools.
If you submit a couple of 10-digit random numbers to your favorite AI assistant and ask it to multiply them, it’s probably not really the neural networks doing the number-crunching work. More likely, it’s a special “tool” known more formally as a “calculator,” which is linked up to the LLM itself. So, behind the scenes, the LLM notices that your request looks like it needs a calculator, because it’s good at recognizing patterns like that, and then calls the internal calculator tool without telling you. The calculator tool is not using neural networks, so it’s literally a billion times faster than the LLM, and you won’t notice any delay from the extra step. Incidentally, I’m referring to the grunt-work calculator tool inside the AI servers next to the LLM code, not the graphical one that you can launch on your laptop or smartphone. After this extra hop, the LLM then combines the output from its calculator tool into a lovely couple of paragraphs, the last of which wraps up with an optimistic offer to “explore” its answer further, should you so wish.
Symbolic Execution
For some strange reason, the programmers that wrote AI engines thought it might be a good idea for an AI to be a programmer in order for it to get smarter. I mean, if I want to train my LLM not to put “rocks” on the grocery list, obviously it would do that better if it spoke to me in Python.
Anyway, here we are: symbolic execution.
Having the model interface with a “symbolic interpreter” or other symbolic representation is one way to improve a model’s reasoning capability. There are various different approaches, ranging from very mathematical logical languages to more compute-related dialects such as executing Python scripts. In this idea, the LLM generates Python as its output, which is then interpreted by a built-in integration. If you prompt the AI with this:
This a test.
Then the AI will generate this intermediate Python program to run:
print("This is indeed a test.")
This is a silly example, because LLMs are certainly smart enough to do different things for different input prompts. Simple prompts do not need symbolic execution. The idea with symbolic execution is that simple prompts are handled the normal way, without coding, whereas complex reasoning type inputs are handled indirectly by generating an executable Python program.
There are some reasons why this indirect approach of generating answers via symbolic execution might work well, at least for a subset of problems. For example, Python programs are more general than LLM’s decoding algorithms:
- Looping-type constructs in programs.
- Hierarchical or recursive logic.
- Second level of indirection capability.
- Turing completeness of computation.
Turing completeness is an obscure Computer Science theory about programming languages, where they must have:
1. Sequence — execute two statements in a row.
2. Selection — an “if” statement that chooses two paths.
3. Iteration — looping around to do it again.
There’s actually a fourth requirement in practice that’s sometimes overlooked in the theoretical treatises:
4. Persistence — ability to store data somewhere (i.e., variables in memory or disk).
LLMs by their lonesome are actually not Turing complete, because they are finite, which means that they miss the third capability. LLM models are a fixed-size data structure with very little looping or “iteration” capability. LLMs are massive, yes, but still finite.
On the other hand, LLMs have all the other requirements, and using a multi-step reasoning algorithm around an LLM can add that type of non-deterministic looping. So, maybe that’s all it needs to be Turing complete.
Symbolic execution has not yet really taken off as a way to improve LLM intelligence, although there are some startups still working on this idea, so who knows where it might go? Perhaps coincidentally, instead of learning coding making LLMs smarter at lots of stuff, LLMs got really good at coding, to the point where the job that is now considered most likely to be fully replaced by AI engines: programmers.
References
Arithmetic Calculations. Research papers on LLM arithmetic limitations, mostly prior to their solution via reasoning models and tool integrations:
- Sean Williams, James Huckle, 30 May 2024, Easy Problems That LLMs Get Wrong, https://arxiv.org/abs/2405.19616 Code: https://github.com/autogenai/easy-problems-that-llms-get-wrong
- Sean McLeish, Arpit Bansal, Alex Stein, Neel Jain, John Kirchenbauer, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, Jonas Geiping, Avi Schwarzschild, Tom Goldstein, 27 May 2024, Transformers Can Do Arithmetic with the Right Embeddings, https://arxiv.org/abs/2405.17399 (Positional encoding of numeric digits improves math arithmetic accuracy.)
- Subhro Roy, Dan Roth, 20 Aug 2016 (v2), Solving General Arithmetic Word Problems, https://arxiv.org/abs/1608.01413
- Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, Dylan Slack, Qin Lyu, Sean Hendryx, Russell Kaplan, Michele (Mike)Lunati, Summer Yue, 1 May 2024, A Careful Examination of Large Language Model Performance on Grade School Arithmetic, https://arxiv.org/abs/2405.00332
- Owen Dugan, Donato Manuel Jimenez Beneto, Charlotte Loh, Zhuo Chen, Rumen Dangovski, Marin Soljačić, 4 Jun 2024, OccamLLM: Fast and Exact Language Model Arithmetic in a Single Step, https://arxiv.org/abs/2406.06576
- Aaditya K. Singh, DJ Strouse, 22 Feb 2024, Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs, https://arxiv.org/abs/2402.14903
- Safal Shrestha, Minwu Kim, Keith Ross, 12 Feb 2025, Mathematical Reasoning in Large Language Models: Assessing Logical and Arithmetic Errors across Wide Numerical Ranges, https://arxiv.org/abs/2502.08680
Calculator Tool Integrations. Research papers on combining calculator tools with LLMs:
- Liu, Z., Zheng, Y., Yin, Z. et al., 2025, ArithmeticGPT: empowering small-size large language models with advanced arithmetic skills, Mach Learn 114, 24 (2025). https://doi.org/10.1007/s10994-024-06681-1 https://link.springer.com/article/10.1007/s10994-024-06681-1 https://github.com/ai4ed/ArithmeticGPT (Integrate a calculator into the processing.)
- reiinakano, November 12, 2019, Teaching a neural network to use a calculator, https://reiinakano.com/2019/11/12/solving-probability.html (Integrate SymPy calculator into the results of a neural network, by looking for the equals sign.)
- Yakun Zhu, Shaohang Wei, Xu Wang, Kui Xue, Xiaofan Zhang, Shaoting Zhang, 17 Oct 2024, MeNTi: Bridging Medical Calculator and LLM Agent with Nested Tool Calling, https://arxiv.org/abs/2410.13610
- Florian Dietz, Dietrich Klakow, 1 Jan 2025, IGC: Integrating a Gated Calculator into an LLM to Solve Arithmetic Tasks Reliably and Efficiently, https://arxiv.org/abs/2501.00684
LLM Chess Limitations. By default, LLMs treat chess moves like words, and struggle to integrate the two-dimensional strategy:
- Dynomight, Nov 2024, Something weird is happening with LLMs and chess, https://dynomight.net/chess/
- Victor Tangermann, Sep 13, 2024, OpenAI’s New “Strawberry” AI Is Still Making Idiotic Mistakes, https://futurism.com/openai-strawberry-o1-mistakes
- Dynomight, Nov 2024, OK, I can partly explain the LLM chess weirdness now, https://dynomight.net/more-chess/
Word Puzzles. Research on LLMs has shown them to be poor at word puzzles, crosswords, and anagrams, although reasoning models starting with the OpenAI “Strawberry” model have improved things:
- Abdelrahman “Boda” Sadallah, Daria Kotova, Ekaterina Kochmar, 15 Mar 2024, Are LLMs Good Cryptic Crossword Solvers? https://arxiv.org/abs/2403.12094 Code: https://github.com/rdeits/cryptics
- Michael King, July 24, 2023, Large Language Models are Extremely Bad at Creating Anagrams, https://www.techrxiv.org/doi/full/10.36227/techrxiv.23712309.v1
- Victor Tangermann, Sep 13, 2024, OpenAI’s New “Strawberry” AI Is Still Making Idiotic Mistakes, https://futurism.com/openai-strawberry-o1-mistakes
- Sam Liberty, Oct 15, 2024, Why AI Can’t Crack the NYT Connections Puzzle (Yet), https://medium.com/design-bootcamp/why-ai-cant-crack-the-nyt-connections-puzzle-yet-7bd3e00b4087
- Reddit, 2024, LLMs can’t solve anagram problems? https://www.reddit.com/r/learnmachinelearning/comments/1cjn5tz/llms_cant_solve_anagram_problems/
Mathematical Reasoning. There are plenty of research papers on empowering LLMs with better mathematical and logical reasoning capabilities:
- Nate Kushman, Yoav Artzi, Luke Zettlemoyer, Regina Barzilay, June 2014, Learning to Automatically Solve Algebra Word Problems, P14-1026 Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), https://aclanthology.org/P14-1026/ PDF: https://aclanthology.org/P14-1026.pdf
- Yan Wang, Xiaojiang Liu, Shuming Shi, September 2017, Deep Neural Solver for Math Word Problems, D17-1088, Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing Copenhagen, Denmark, https://aclanthology.org/D17-1088/ PDF: https://aclanthology.org/D17-1088.pdf
- Guoxin Chen, Minpeng Liao, Chengxi Li, Kai Fan, 6 May 2024, AlphaMath Almost Zero: process Supervision without process, https://arxiv.org/abs/2405.03553 https://github.com/MARIO-Math-Reasoning/Super_MARIO
- Shima Imani, Liang Du, and H. Shrivastava, 2023, Mathprompter: Mathematical reasoning using large language models, ArXiv, abs/2303.05398, https://arxiv.org/abs/2303.05398
- Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, Wenpeng Yin, 5 Apr 2024 (v3), Large Language Models for Mathematical Reasoning: Progresses and Challenges, https://arxiv.org/abs/2402.00157
- Luyu Qiu, Jianing Li, Chi Su, Chen Jason Zhang, Lei Chen, 22 Jul 2024, Dissecting Multiplication in Transformers: Insights into LLMs, https://arxiv.org/abs/2407.15360
- Bbot, 2024, Why is GPT bad at math? Because it can’t see digits! https://bbot.org/etc/gpt-math.png
- Andrew Blair-Stanek, Nils Holzenberger, Benjamin Van Durme, 7 Feb 2024 (v2), OpenAI Cribbed Our Tax Example, But Can GPT-4 Really Do Tax? https://arxiv.org/abs/2309.09992
- Asir Saadat, Tasmia Binte Sogir, Md Taukir Azam Chowdhury, Syem Aziz, 16 Oct 2024, When Not to Answer: Evaluating Prompts on GPT Models for Effective Abstention in Unanswerable Math Word Problems, https://arxiv.org/abs/2410.13029
- Amogh Akella, 29 Oct 2024, Problem Categorization Can Help Large Language Models Solve Math Problems, https://arxiv.org/abs/2411.00042
- Michael Nuñez, November 11, 2024, AI’s math problem: FrontierMath benchmark shows how far technology still has to go, https://venturebeat.com/ai/ais-math-problem-frontiermath-benchmark-shows-how-far-technology-still-has-to-go/
- Yibo Yan, Jiamin Su, Jianxiang He, Fangteng Fu, Xu Zheng, Yuanhuiyi Lyu, Kun Wang, Shen Wang, Qingsong Wen, Xuming Hu, 6 Dec 2024, A Survey of Mathematical Reasoning in the Era of Multimodal Large Language Model: Benchmark, Method & Challenges, https://arxiv.org/abs/2412.11936
- Shuguang Chen, Guang Lin, 28 Dec 2024, LLM Reasoning Engine: Specialized Training for Enhanced Mathematical Reasoning, https://arxiv.org/abs/2412.20227
- Beichen Zhang, Yuhong Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Haodong Duan, Yuhang Cao, Dahua Lin, Jiaqi Wang, 6 Jan 2025, BoostStep: Boosting mathematical capability of Large Language Models via improved single-step reasoning, https://arxiv.org/abs/2501.03226 https://github.com/beichenzbc/BoostStep
- xenaproject, December 22, 2024, Can AI do maths yet? Thoughts from a mathematician, https://xenaproject.wordpress.com/2024/12/22/can-ai-do-maths-yet-thoughts-from-a-mathematician/
- Zain Ul Abedin, Shahzeb Qamar, Lucie Flek, Akbar Karimi, 14 Jan 2025, ArithmAttack: Evaluating Robustness of LLMs to Noisy Context in Math Problem Solving, https://arxiv.org/abs/2501.08203
- Ali Forootani, 22 Mar 2025, A Survey on Mathematical Reasoning and Optimization with Large Language Models, https://arxiv.org/abs/2503.17726
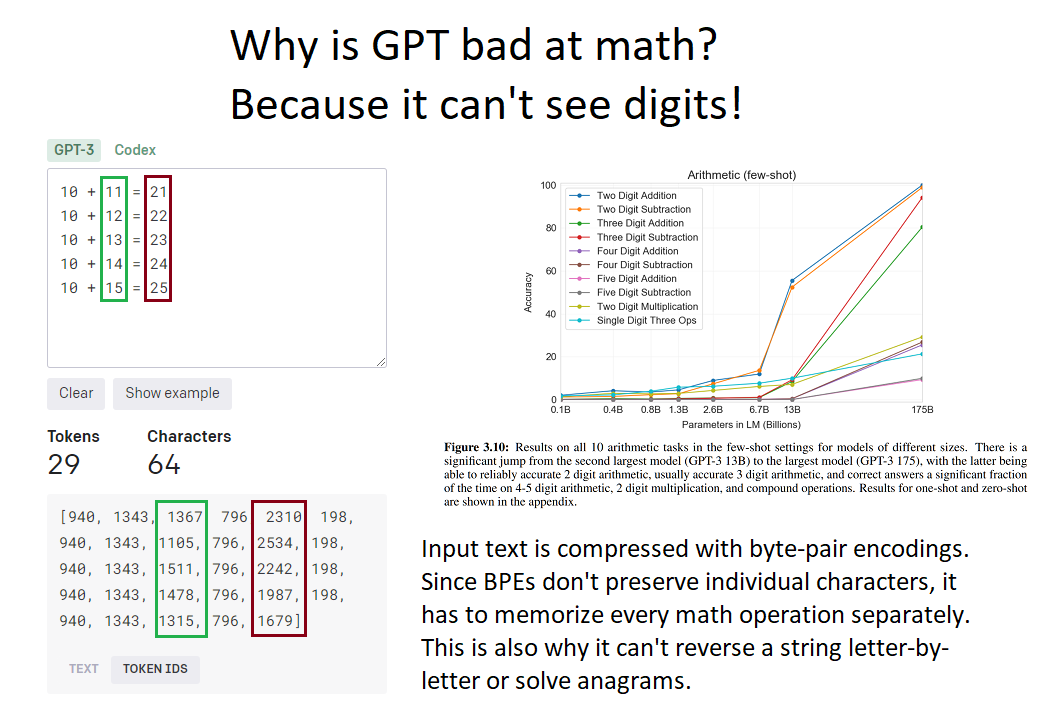{kind=link}
Symbolic Execution. The use of a sequence of symbols in either a logical language or a real programming language, which is then executed as a program or “script” can create a type of advanced reasoning, especially in mathematical and reasoning domains. Research papers include:
- Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen, 2022, Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks, arXiv preprint arXiv:2211.12588, 2022, https://arxiv.org/abs/2211.12588 (Integrate a Python interpreter to execute the code generated by the LLM to answer the query.)
- Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig, 2023, Pal: Program-aided language models. In International Conference on Machine Learning, pages 10764–10799. PMLR, https://arxiv.org/abs/2211.10435 Code: http://reasonwithpal.com/ (Python interpreter integrated as a tool for LLMs.)
- Long Hei Matthew Lam, Ehsan Shareghi, 1 Jun 2024, A Closer Look at Logical Reasoning with LLMs: The Choice of Tool Matters, https://arxiv.org/abs/2406.00284 (Using symbolic solvers with LLMs.)
- M Keber, I Grubišic, A Barešic, A Jovic, 2024, A Review on Neuro-symbolic AI Improvements to Natural Language Processing, https://www.researchgate.net/profile/Alan-Jovic/publication/380911364_A_Review_on_Neuro-symbolic_AI_Improvements_to_Natural_Language_Processing/links/6655c0ec22a7f16b4f51fb2f/A-Review-on-Neuro-symbolic-AI-Improvements-to-Natural-Language-Processing.pdf
- Joy He-Yueya, Gabriel Poesia, Rose E. Wang, and Noah D. Goodman, 2023, Solving math word problems by combining language models with symbolic solvers, ArXiv, abs/2304.09102, https://arxiv.org/abs/2304.09102
- Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, Mehrdad Farajtabar, 7 Oct 2024, GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models, https://arxiv.org/abs/2410.05229
- Mayi Xu, Yunfeng Ning, Yongqi Li, Jianhao Chen, Jintao Wen, Yao Xiao, Shen Zhou, Birong Pan, Zepeng Bao, Xin Miao, Hankun Kang, Ke Sun, Tieyun Qian, 2 Jan 2025, Reasoning based on symbolic and parametric knowledge bases: a survey, https://arxiv.org/abs/2501.01030 (Extensive survey of reasoning from CoT to knowledge graphs to table-based reasoning.)
- Yixuan Li, Lewis Frampton, Federico Mora, Elizabeth Polgreen, 9 Jan 2025, Online Prompt and Solver Selection for Program Synthesis, https://arxiv.org/abs/2501.05247
- Benjamin Callewaert, Simon Vandevelde, Joost Vennekens, 24 Jan 2025, VERUS-LM: a Versatile Framework for Combining LLMs with Symbolic Reasoning, https://arxiv.org/abs/2501.14540
- Yubin Ge, Salvatore Romeo, Jason Cai, Raphael Shu, Monica Sunkara, Yassine Benajiba, Yi Zhang, 3 Feb 2025, TReMu: Towards Neuro-Symbolic Temporal Reasoning for LLM-Agents with Memory in Multi-Session Dialogues, https://arxiv.org/abs/2502.01630
- Siheng Xiong, Jieyu Zhou, Zhangding Liu, Yusen Su, 2 May 2025, SymPlanner: Deliberate Planning in Language Models with Symbolic Representation, https://arxiv.org/abs/2505.01479
- Adam Stein, Aaditya Naik, Neelay Velingker, Mayur Naik, Eric Wong, 30 May 2025, The Road to Generalizable Neuro-Symbolic Learning Should be Paved with Foundation Models, https://arxiv.org/abs/2505.24874
|
Sweetest Lesson AI Book: • Online: Table of Contents • PDF: Free PDF book download |

|
The Sweetest Lesson: Your Brain Versus AI: new book on AI intelligence theory:
Get your copy from Amazon: The Sweetest Lesson |